SQL Subquery
Table of contents
Subquery Basic
다른 SELECT문의 질의에 삽입된 쿼리문
▸ 서브쿼리는 괄호로 묶어야 하며 비교 조건의 오른쪽에 넣음
▸ 메인쿼리 : 외부에 기술하는 쿼리, 서브쿼리 : 내부에 기술하는 쿼리
▸ 메인 쿼리에 사용할 값을 반환함, 서브쿼리에서 실행된 결과가 메인 쿼리에 전달되어 최종적인 결과를 출력
▸ 서브쿼리의 결과값의 개수에 의해서 단일 행 서브 쿼리와 다중 행 서브 쿼리로 나뉨
▸ 그룹 함수를 서브쿼리에 사용하는 경우에도 그룹함수가 단일 행을 결과값으로 구하기 때문에 단일 행 서브쿼리에 해당
단일 행 비교연산자 : >, =, <, >=, <=, <>
다중 행 비교연산자 : IN, ANY, SOME, ALL, EXISTS
syntax
SELECT select_list
FROM table
WHERE expr OPERATOR (SELECT …)
▸ OPERATOR는 단일 행 비교연산자와 다중 행 비교연산자로 나뉨 (섞어서 사용할 수 없음)
-- SMITH와 동일한 부서에서 일하는 사람들의 이름과 부서번호 구하기
select ENAME, DEPTNO
from emp
WHERE DEPTNO = (select deptno from emp where ename = 'SMITH');
Subquery Sort
연관성에 따른 분류
1) 연관성이 있는 서브쿼리
2) 연관성이 없는 서브쿼리
위치에 따른 분류
1) 인라인뷰 : select or from 절에 위치
2) 중첩쿼리 : where 절에 위치
Subquery Column
컬럼에 서브쿼리문을 사용해서 테이블을 조인하고 값을 가져올 수 있음
→ 일반적으로 테이블 조인해서 값 가져오는 방법
select emp.first_name, emp.last_name, emp.department_id, dpt.department_name
from hr.employees emp, hr.departments dpt
where emp.department_id = dpt.department_id
order by emp.first_name;
→ 서브쿼리문을 사용해서 값을 가져오는 방법
select emp.first_name, emp.last_name, emp.department_id,
(select department_name from hr.departments dpt where dpt.department_id = emp.department_id)
from hr.employees emp
order by emp.first_name;
Subquery Update
다중로우, 다중컬럼을 이용한 update처리하기
→ 각각 설정하기
update month_salary sal
set sal.emp_count = (select count(*)
from employees emp
where emp.department_id = sal.department_id
group by department_id)
, sal.total_salary = (select sum(salary) from employees emp
where emp.department_id = sal.department_id
group by department_id)
, sal.average_salary = (select round(avg(salary)) from employees emp
where emp.department_id = sal.department_id
group by department_id);
→ 한번에 설정하기
update month_salary sal
set (sal.emp_count, sal.total_salary, sal.average_salary)
= (select count(*), sum(salary), round(avg(salary))
from employees emp
where emp.department_id = sal.department_id
group by department_id);
Multiple Row Subquery
서브 쿼리에서 반환되는 결과가 하나 이상의 행일 때 사용
▸ 다중 행 서브쿼리는 반드시 다중 행 연산자와 함께 사용해야 함
| 종류 | 의미 |
|---|---|
| IN | 메인 쿼리의 비교조건(= 연산자로 비교할경우)이 서브쿼리의 결과중에서 하나라도 일치하면 참 |
| ANY,SOME | 메인쿼리의 비교조건이 서브쿼리의 검색 결과와 하나 이상이 일치하면 참 |
| ALL | 메인 쿼리의 비교 조건이 서브 쿼리의 검색 결과와 모든 값이 일치하면 참 |
| EXIST | 메인쿼리의 비교조건이 서브 쿼리의 결과 중에서 만족하는 값이 하나라도 존재하면 참 |
IN Operator
메인 쿼리의 비교조건(= 연산자로 비교할경우)이 서브쿼리의 결과중에서 하나라도 일치하면 참
▸ =ANY와 동일함
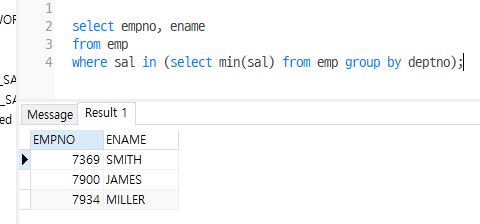
--부서별 최소 급여를 받는 사원의 사원번호와 이름을 출력
select empno, ename
from emp
where sal in (select min(sal) from emp group by deptno);
ANY Operator
메인쿼리의 비교조건이 서브쿼리의 검색 결과와 하나 이상이 일치하면 참
서브쿼리가 반환하는 각각의 값과 비교함
<ANY : 결과중에 최대값을 리턴, 최대값보다 작음
ANY : 결과중에 최소값을 리턴, 최소값보다 큼
- =ANY : IN과동일
--직급이 SALESMAN이 아니면서 급여가 임의의 SALESMAN보다 낮은 사원을 출력
-- salesman의 최대급여 아래로 나옴
select empno, ename, job, sal
from emp
where sal < any (select sal from emp where job = 'SALESMAN')
and job <> 'SALESMAN'
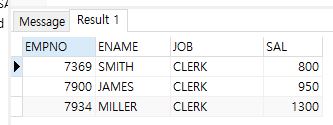
ALL Operator
메인 쿼리의 비교 조건이 서브 쿼리의 검색 결과와 모든 값이 일치하면 참
서브쿼리가 반환하는 모든 값과 비교
>ALL : 결과중에 최대값을 리턴, 최대값보다 큼
<ALL : 결과중에 최소값을 리턴, 최소값보다 작음
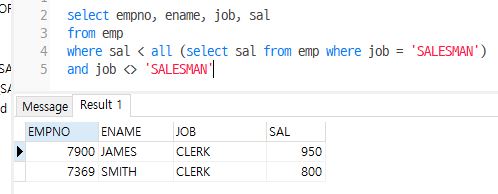
-- 직급이 SALESMAN이 아니면서 급여가 SALESMAN보다 낮은 사원을 출력
-- salesman의 최소급여 아래로 나옴
select empno, ename, job, sal
from emp
where sal < all (select sal from emp where job = 'SALESMAN')
and job <> 'SALESMAN'
Virtual Table with Subquery
WITH Clause
1회성 테이블처럼 임시로 사용하고자 할 경우에는 ‘with’절을 사용하여 가상테이블 처럼 사용
syntax
with 가상테이블명 as
(subquery)
select 컬럼명 from 가상테이블명 – 꼭 같이 사용해야함
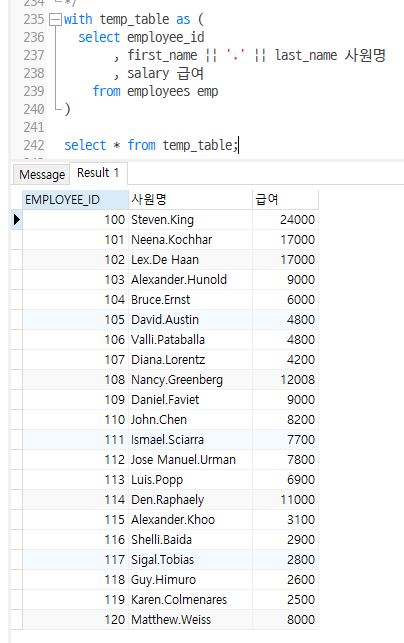
with temp_table
as
(select employee_id, first_name || '.' || last_name 사원명, salary 급여
from employees emp)
select * from temp_table;
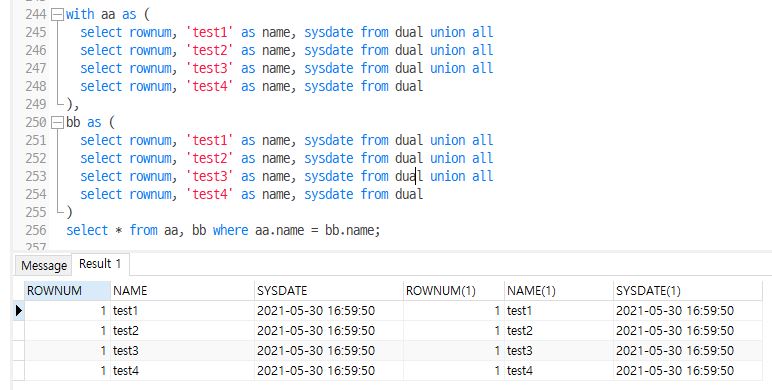
with aa as (
select rownum, 'test1' as name, sysdate from dual union all
select rownum, 'test2' as name, sysdate from dual union all
select rownum, 'test3' as name, sysdate from dual union all
select rownum, 'test4' as name, sysdate from dual
),
bb as (
select rownum, 'test1' as name, sysdate from dual union all
select rownum, 'test2' as name, sysdate from dual union all
select rownum, 'test3' as name, sysdate from dual union all
select rownum, 'test4' as name, sysdate from dual
)
select * from aa, bb where aa.name = bb.name;
Example
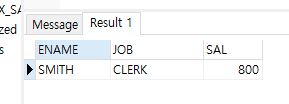
Q1. 최소급여를 받는 사원의 이름, 담당업무, 급여 출력
select ename, job, sal
from emp
where sal = (select min(sal) from emp);
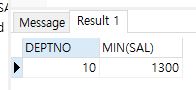
Q2. 부서별 최소 급여가 30번부서의 최소급여보다 큰 부서만 출력
select deptno, min(sal)
from emp
group by deptno
having min(sal) > (select min(sal) from emp where deptno = 30)
Q3. hr계정의 사원테이블에서 평균급여보다 작은 사원만 출력
-- 1. 사원테이블의 평균급여 구하기
select round(avg(salary)) from hr.employees emp;
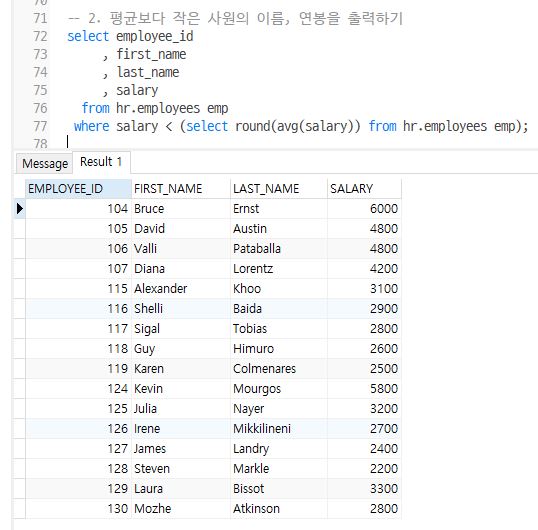
-- 2. 평균보다 작은 사원의 이름, 연봉을 출력하기
select employee_id, first_name, last_name, salary
from hr.employees emp
where salary < (select round(avg(salary)) from hr.employees emp);
Q4. 월급이 가장많은 사원 (first_name, last_name, job_title)
-- 00. 테이블 조회
select * from employees;
select * from jobs;
-- 01. 월급이 가장 많은 사원 조회
select max(salary) from employees;
-- 02. 테이블 조인 후 서브쿼리로 조건을 건후 출력
select emp.first_name, emp.last_name, job.job_title, emp.salary
from employees emp, jobs job
where emp.job_id = job.job_id
and emp.salary = (select max(salary) from employees);

Q5. 월급이 가장적은 사원 (first_name, last_name, job_title)
select emp.first_name, emp.last_name, job.job_title, emp.salary
from employees emp, jobs job
where emp.job_id = job.job_id
and emp.salary = (select min(salary) from employees);

Q6. 월급이 미국내에서 근무하는 사원들의 평균급여보다 많은 사원 (first_name, last_name, job_title)
– locations의 country_id = ‘US’
– hint) 서브쿼리안엔 employees, departments, locations
-- 00. 테이블 조회
select * from locations where country_id = 'US';
select * from departments;
select * from employees;
-- 01. 미국 내에서 근무하는 사원들의 평균급여
select round(avg(emp.salary))
from employees emp, departments dpt, locations loc
where loc.country_id = 'US'
and loc.location_id = dpt.location_id
and emp.department_id = dpt.department_id;
-- 02. 뷰생성후 테이블 조인 후 평균급여보다 많은 사원 조회
create or replace view v_over_avg_salary_by_us
as
select emp.first_name, emp.last_name, emp.salary, job.job_title
from employees emp, jobs job
where emp.job_id = job.job_id
and emp.salary > (select round(avg(emp.salary))
from employees emp, departments dpt, locations loc
where loc.country_id = 'US'
and loc.location_id = dpt.location_id
and emp.department_id = dpt.department_id);
-- 03. 뷰 조회
select * from v_over_avg_salary_by_us;

Assignment
- 급여가 평균보다 같거나 큰 그리고 최대급여보다 작거나 같은 사원출력
– 사원번호 사원명(f_name + l_name), salary / 순서는 급여많은 순으로
-- 01. 테이블 조회
select * from employees;
-- 02. 급여의 평균
select avg(sal) from employees;
-- 03. 최대급여
select max(sal) from employees;
-- 04. 출력
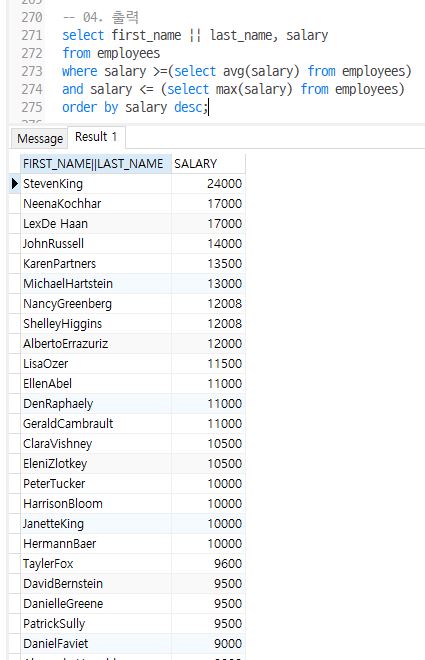
select first_name || last_name, salary
from employees
where salary >=(select avg(salary) from employees)
and salary <= (select max(salary) from employees)
order by salary desc;
- 사원테이블에서 입사월별로 인원수를 출력
– group by 입사월, order by 입사월
-- 01. 테이블 조회
select * from employees;
-- 02. 세로로 출력
select substr(hire_date,6,2) || '월' 입사월, count(*) 사원수
from employees
group by substr(hire_date,6,2)
order by substr(hire_date,6,2);
-- 03. 가로로 출력
select sum(M01) "1월",
sum(M02) "2월",
sum(M03) "3월",
sum(M04) "4월",
sum(M05) "5월",
sum(M06) "6월",
sum(M07) "7월",
sum(M08) "8월",
sum(M09) "9월",
sum(M010) "10월",
sum(M011) "11월",
sum(M012) "12월"
from
(select decode(to_char(hire_date,'MM'), '01', count(*), 0) M01, -- 1월
decode(to_char(hire_date,'MM'), '02', count(*), 0) M02, -- 1월
decode(to_char(hire_date,'MM'), '03', count(*), 0) M03, -- 1월
decode(to_char(hire_date,'MM'), '04', count(*), 0) M04, -- 1월
decode(to_char(hire_date,'MM'), '05', count(*), 0) M05, -- 1월
decode(to_char(hire_date,'MM'), '06', count(*), 0) M06, -- 1월
decode(to_char(hire_date,'MM'), '07', count(*), 0) M07, -- 1월
decode(to_char(hire_date,'MM'), '08', count(*), 0) M08, -- 1월
decode(to_char(hire_date,'MM'), '09', count(*), 0) M09, -- 1월
decode(to_char(hire_date,'MM'), '10', count(*), 0) M010, -- 1월
decode(to_char(hire_date,'MM'), '11', count(*), 0) M011, -- 1월
decode(to_char(hire_date,'MM'), '12', count(*), 0) M012 -- 1월
from employees
group by to_char(hire_date, 'MM')
order by to_char(hire_date, 'MM'));

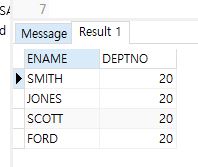
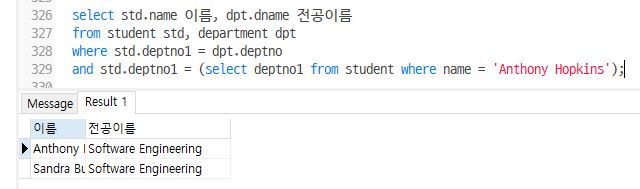
- student, department에서 ‘Anthony Hopkins’학생과 1전공이 동일한 학생들의 이름과 1전공이름을 출력
select std.name 이름, dpt.dname 전공이름
from student std, department dpt
where std.deptno1 = dpt.deptno
and std.deptno1 = (select deptno1 from student where name = 'Anthony Hopkins');
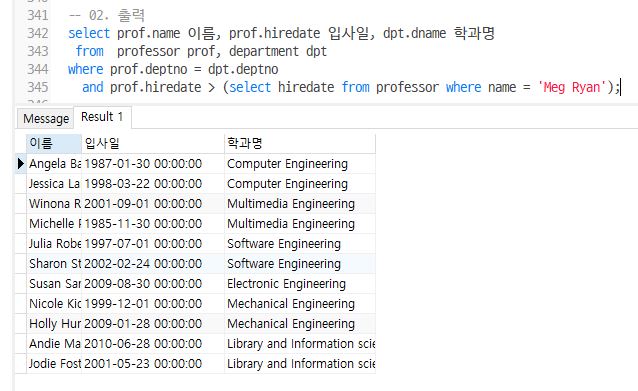
- professor, department를 조회해서 ‘Meg Ryan’교수보다 나중에입사한 사람들의 이름과 입사일과 학과명을 출력
-- 00. 테이블 조회
select * from professor;
select * from department;
-- 01. Meg Ryan 교수의 입사일
select hiredate from professor where name = 'Meg Ryan';
-- 02. 출력
select prof.name 이름, prof.hiredate 입사일, dpt.dname 학과명
from professor prof, department dpt
where prof.deptno = dpt.deptno
and prof.hiredate > (select hiredate from professor where name = 'Meg Ryan');
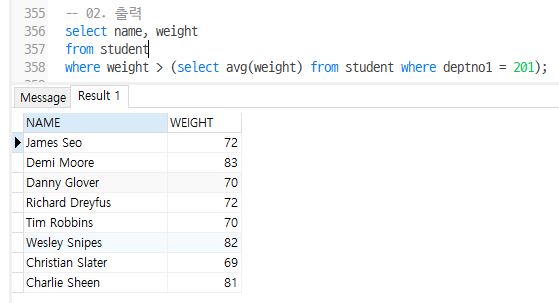
- student에서 1전공(deptno1)이 201번인 학과의 평균몸무게보다 몸무게가 많은 학생들의 이름과 몸무게를 출력
-- 01. 전공이 201번인 학과의 평균몸무게
select avg(weight) from student where deptno1 = 201;
-- 02. 출력
select name, weight
from student
where weight > (select avg(weight) from student where deptno1 = 201);
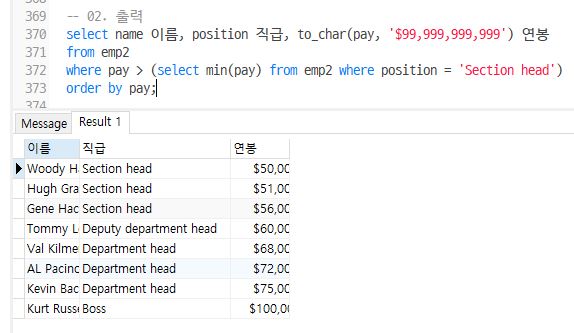
- emp2에서 전체직원중 ‘Section head’직급의 최소연봉자보다 연봉이 높은 사람의 이름과 직급, 연봉을 출력 – 단, 급여는 $9,999,999형식으로 출력
-- 00. 테이블 조회
select * from emp2;
-- 01. 'Section head'직급의 최소연봉자
select min(pay) from emp2 where position = 'Section head';
-- 02. 출력
select name 이름, position 직급, to_char(pay, '$99,999,999,999') 연봉
from emp2
where pay > (select min(pay) from emp2 where position = 'Section head')
order by pay;
-- 03. 같은 문법
-- where pay > any (select min(pay) from emp2 where position = 'Section head')
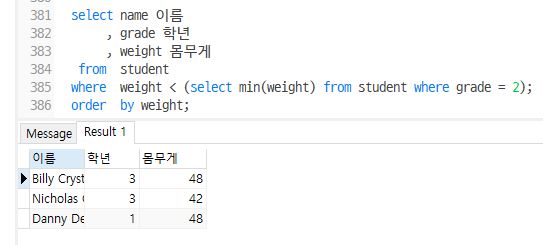
- student에서 전체학생중 체중이 2학년학생들의 체중에서 가장 적게 나가는 학생보다 몸무게게 적은 학생의 이름과 학년과 몸무게 출력
select name 이름
, grade 학년
, weight 몸무게
from student
where weight < (select min(weight) from student where grade = 2);
order by weight;
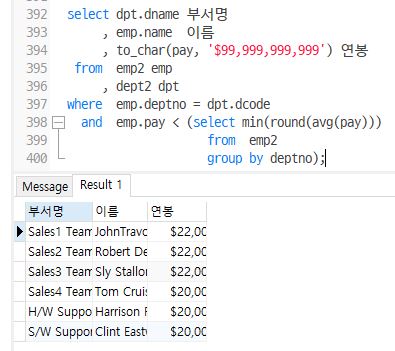
- emp2,dept2에서 각 부서별 평균연봉과 그중에서 평균연봉이 가장 적은 부서의 평균연봉보다 적게 받는 직원들의 부서명, 직원명, 연봉을 출력 (연봉은 $999,999,999)
select dpt.dname 부서명
, emp.name 이름
, to_char(pay, '$99,999,999,999') 연봉
from emp2 emp
, dept2 dpt
where emp.deptno = dpt.dcode
and emp.pay < (select min(round(avg(pay)))
from emp2
group by deptno);
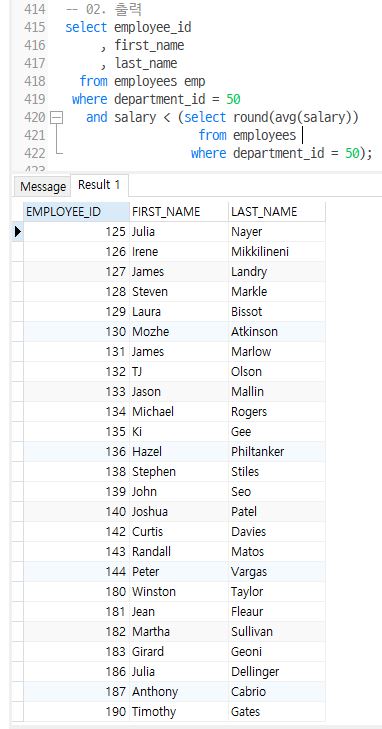
- 물류 부서에 속한 사원들 중, 물류 부서의 평균 급여보다 낮은 월급을 받는 사원 명단을 조회하는 쿼리를 작성(인라인뷰로 작성, 물류부서는 50)
-- 00. 테이블 조회
select * from employees;
select * from departments;
-- 01. 물류부서의 평균급여 조회
select round(avg(salary))
from employees
where department_id = 50
-- 02. 출력
select employee_id
, first_name
, last_name
from employees emp
where department_id = 50
and salary < (select round(avg(salary))
from employees
where department_id = 50);
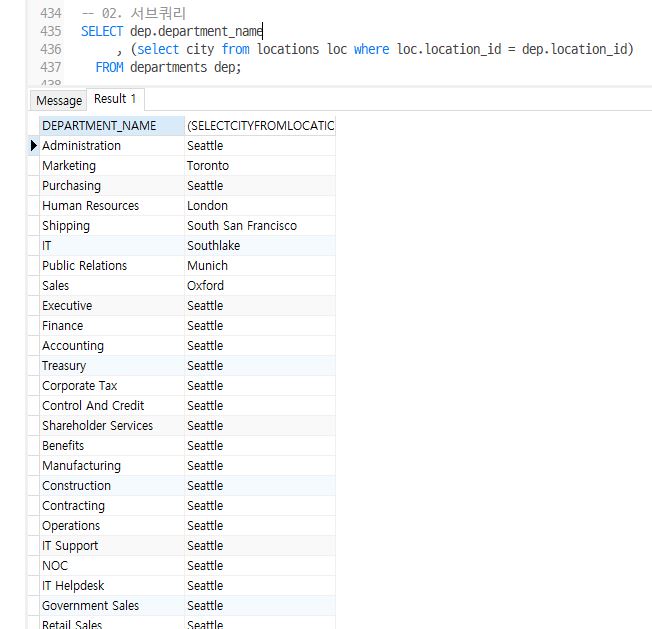
- 다음 문장은 부서 테이블을 조회해서 부서가 위치한 도시명조회 쿼리
– 테이블 조인을 사용하지 말고, 서브쿼리를 사용해서 바꿔보자.
-- 01. 테이블 조인
SELECT dep.department_name,
loc.city
FROM departments dep,
locations loc
WHERE dep.location_id = loc.location_id
-- 02. 서브쿼리
SELECT dep.department_name
, (select city from locations loc where loc.location_id = dep.location_id)
FROM departments dep;
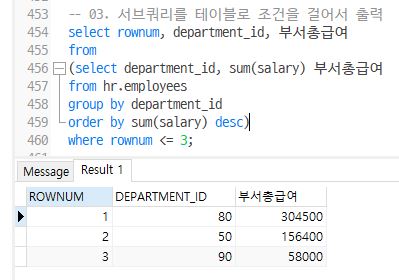
- 부서별 월급 총액이 가장 많은 순서대로 3위까지 해당되는 부서와 월급 총액을 구하는 쿼리를 작성
-- 00. 테이블 조회
select * from employees;
-- 01. 부서별 월급 총액을 구하고 많은 순서대로 정렬
select department_id, sum(salary) 부서총급여
from hr.employees
group by department_id
order by sum(salary) desc;
-- 02. 3번째까지 출력
select rownum from hr.departments where rownum <= 3;
-- 03. 서브쿼리를 테이블로 조건을 걸어서 출력
select rownum, department_id, 부서총급여
from
(select department_id, sum(salary) 부서총급여
from hr.employees
group by department_id
order by sum(salary) desc)
where rownum <= 3;
-- 04. 다른 방법
select dpt.department_name 부서명
, 부서총급여
from departments dpt
, (select department_id
, sum(salary) 부서총급여
from hr.employees
group by department_id
order by sum(salary) desc) sal
where rownum <= 3
and dpt.department_id = sal.department_id;