SQL Single String Function
Table of contents
String Functions
대소문자를 변환하거나 문자열의 길이를 반환하거나 데이터를 조작하는 함수 등으로 나뉨
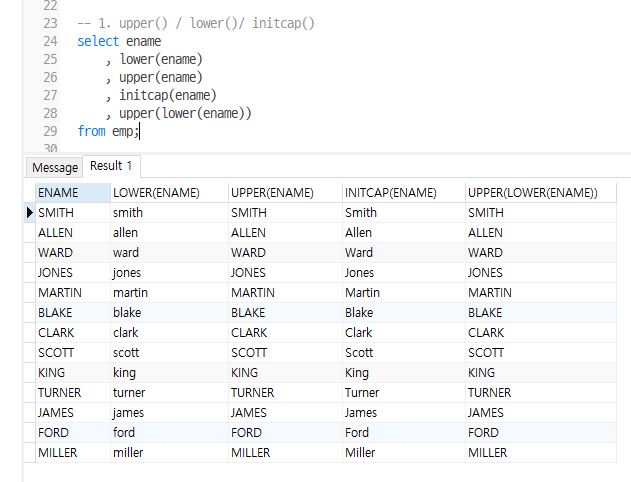
upper() / lower() / initcap()
대소문자 변환 함수
syntax
upper() : 소문자를 대문자로 변환
lower() : 대문자를 소문자로 변환
initcap() : 첫글자를 대문자, 나머지는 소문자로 변환
▸ ()안에는 문자열이나 함수, 열이름(데이터 타입 문자열)등이 들어갈 수 있음
-- upper(lower(ename))는 소문자 변환한걸 대문자로 다시 변환한 모습
select ename
, lower(ename)
, upper(ename)
, initcap(ename)
, upper(lower(ename))
from emp;
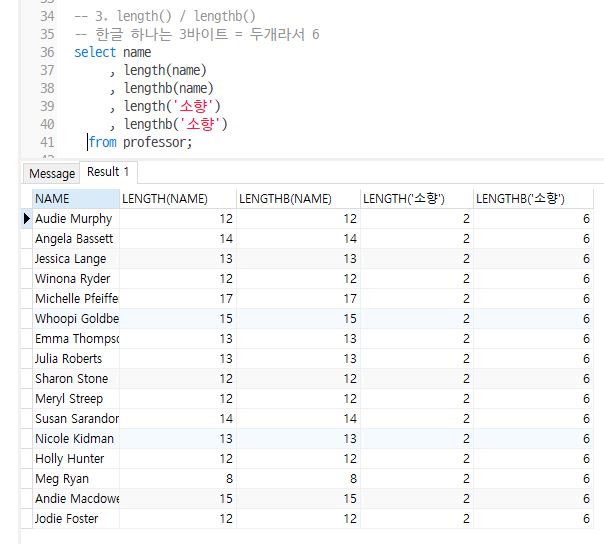
length() / lengthb()
문자 길이를 반환하는 함수
syntax
length() : 문자길이를 리턴(한글인 경우 1byte)
lengthb() : 문자길이를 리턴(한글인 경우 2byte)
▸ ()안에는 문자열이나 함수, 열이름(데이터 타입 문자열)등이 들어갈 수 있음
-- 한글 하나는 3바이트 = 두개라서 6
select name
, length(name)
, lengthb(name)
, length('소향')
, lengthb('소향')
from professor;
한글을 3Byte로 인식할 때
오라클 설치 시 문자 집합을 어떻게 설정했느냐에 따라 한글을 인식하는 Byte의 길이가 달라짐
▸ KO16KSC5601이나 KO16MSWIN949는 한글 한 글자를 2Byte로 인식
▸ UTF8이나 AL32UTF8의 경우 한글 한 글자를 3Byte로 인식 → 한글 정렬이 가능하다는 장점이 있음
→ 아래 코드는 사용중인 문자 집합을 확인할 수 있음
-- SQL PLUS 접속
SQL > SELECT * FROM NLS_DATABASE_PARAMETERS WHERE PARAMETER LIKE '%CHARACTERSET%';
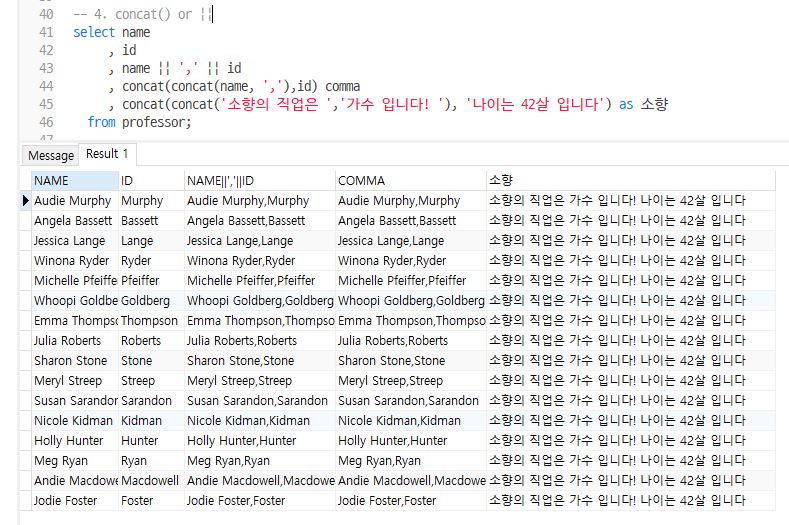
concat()
문자 연결 함수
▸ concat()과 ||은 동일하게 작동함
syntax
concat() : 문자의 값을 연결
▸ ()안에는 문자열이나 함수, 열이름 등이 들어갈 수 있음
select name
, id
, name || ',' || id
, concat(concat(name, ','),id) comma
, concat(concat('소향의 직업은 ','가수 입니다! '), '나이는 42살 입니다') as 소향
from professor;
substr() / substrb()
문자 추출 함수
▸ 한글 같은 경우 문자단위로 자를때 깨지는 경우가 있어서 substrb인 바이트 단위로 자르면 깨지는걸 방지할 수 있음
→ 바이트를 잘못 설정해서 자르면 값이 있긴 한데 제대로 된 값이 아님 (공백인데 값이 있는 공백으로 출력)
syntax
substr(값, from, length) : 주어진 문자에서 문자 단위로 자를때 추출
substrb(값, from, length) : 주어진 문자에서 바이트 단위로 문자열을 자를때 사용
▸ from부터 시작, length갯수 만큼 자름
▸ from에서 음수값이 들어갈경우 뒤에서부터 셈
-- 오라클 설정이 utf8로 되어있어서 한글 한글자는 3byte
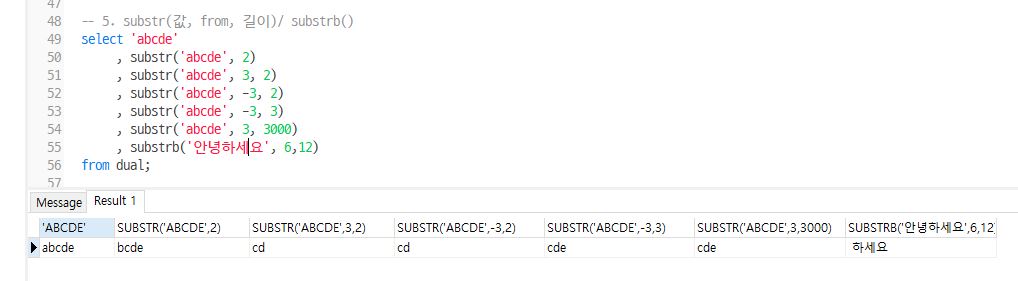
select 'abcde'
, substr('abcde', 2)
, substr('abcde', 3, 2)
, substr('abcde', -3, 2)
, substr('abcde', -3, 3)
, substr('abcde', 3, 3000)
, substrb('안녕하세요', 6,12)
from dual;
!note
한글에 substrb()사용시 제대로 바이트값을 지정하지 않으면 비정상적인 값이 출력됨 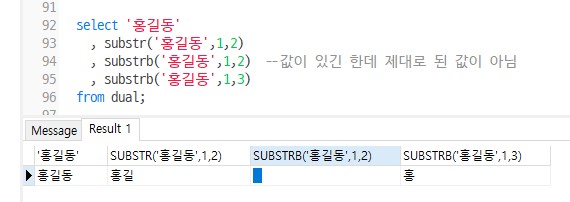
select '홍길동'
, substr('홍길동',1,2)
, substrb('홍길동',1,2) --값이 있긴 한데 제대로 된 값이 아님
, substrb('홍길동',1,3)
from dual;
instr() / instrb()
문자의 위치값을 반환하는 함수
▸ 음수값이 들어가면 뒤에서부터 찾지만, 값은 앞에서부터 세서 출력해줌
▸ 시작위치, 몇번째 인수는 생략할 수 있음, 기본값 둘다 1
syntax
instr(문자열, 찾는글자, 시작위치, 몇번째(기본값 1)) : 주어진 문자에서 특정문자의 위치를 리턴
instrb(문자열, 찾는글자, 시작위치, 몇번째(기본값 1)) 주어진 문자에서 특정문자의 위치 바이트를 리턴
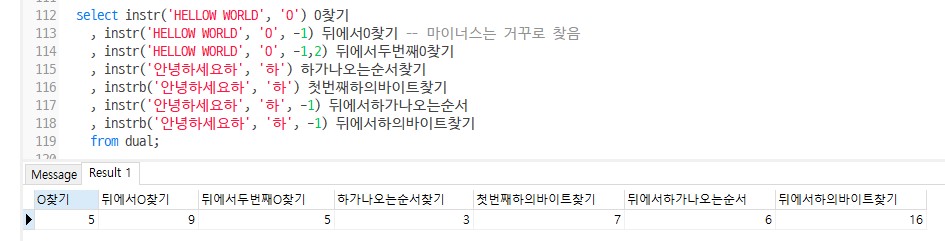
select instr('HELLOW WORLD', 'O') O찾기
, instr('HELLOW WORLD', 'O', -1) 뒤에서O찾기 -- 마이너스는 거꾸로 찾음
, instr('HELLOW WORLD', 'O', -1,2) 뒤에서두번째O찾기
, instr('안녕하세요하', '하') 하가나오는순서찾기
, instrb('안녕하세요하', '하') 첫번째하의바이트찾기
, instr('안녕하세요하', '하', -1) 뒤에서하가나오는순서
, instrb('안녕하세요하', '하', -1) 뒤에서하의바이트찾기
from dual;
lpad() / rpad()
조건에 따라 특정 길이의 문자를 반환하는 함수
syntax
lpad(문자열, 총 문자열 자리수, 나머지 문자열에 채울문자) : 주어진 문자열에서 왼쪽으로 특정 문자를 채움
rpad(문자열, 총 문자열 자리수, 나머지 문자열에 채울문자) : 주어진 문자열에서 오른쪽으로 특정 문자를 채움
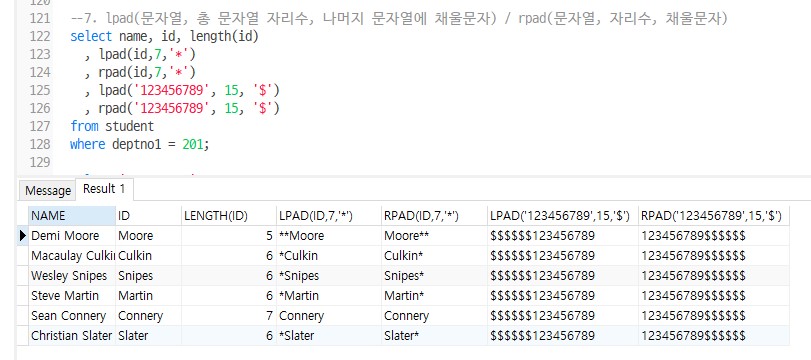
select name, id, length(id)
, lpad(id,7,'*')
, rpad(id,7,'*')
, lpad('123456789', 15, '$')
, rpad('123456789', 15, '$')
from student
where deptno1 = 201;
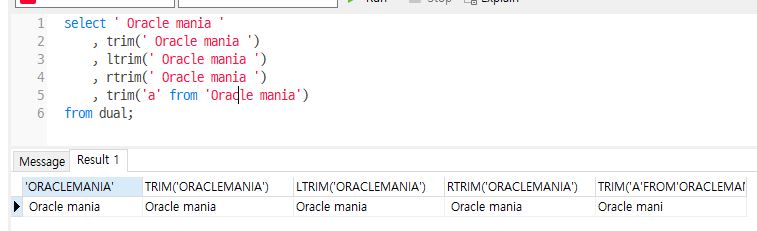
trim() / ltrim() / rtrim()
문자를 다듬는 함수
syntax
trim(문자열, 양쪽에서 자를 문자) : 칼럼이나 대상 문자열에서 특정 문자가 첫 번째 글자이거나 마지막 글자이면 잘라내고 남은 문자열만 반환
ltrim(문자열, 왼쪽에서 자를 문자) : 주어진 문자열에서 왼쪽의 특정 문자나 공백를 삭제
rtrim(문자열, 오른쪽에서 자를 문자) : 주어진 문자열에서 오른쪽의 특정 문자나 공백 문자를 삭제
select ' Oracle mania '
, trim(' Oracle mania ')
, ltrim(' Oracle mania ')
, rtrim(' Oracle mania ')
, trim('O' from 'Oracle mania')
from dual;
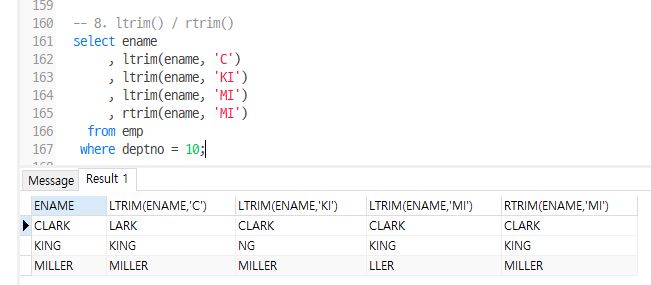
select ename
, ltrim(ename, 'C')
, ltrim(ename, 'KI')
, ltrim(ename, 'MI')
, rtrim(ename, 'MI')
from emp
where deptno = 10;
replace()
문자열을 다른 문자열로 치환하는 함수
syntax
replace(문자열, 변경전문자, 변경후문자)
select ename
, replace(ename, 'KI', '**')
, replace(ename, 'I', '------')
, replace(ename, substr(ename,1,2), '**')
from emp
where deptno = 10;

Example
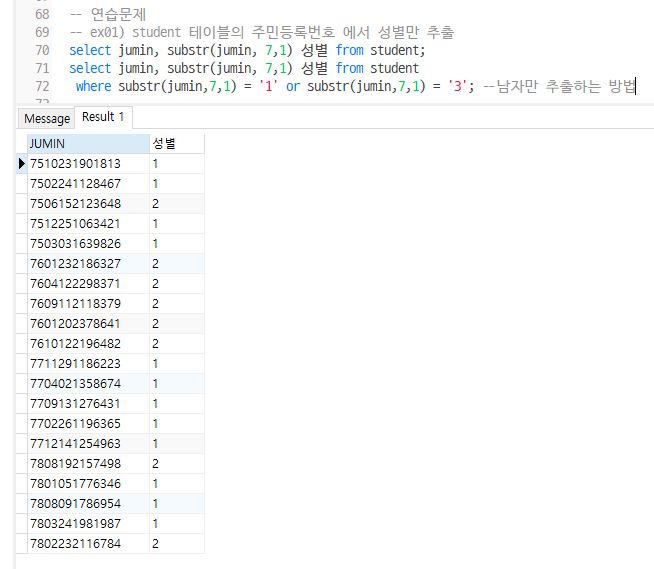
Q1. STUDENT 테이블의 주민등록번호(JUNIN)에서 성별만 추출
select jumin, substr(jumin, 7,1) 성별 from student;
select jumin, substr(jumin, 7,1) 성별 from student
where substr(jumin,7,1) = '1' or substr(jumin,7,1) = '3'; --남자만 추출하는 방법
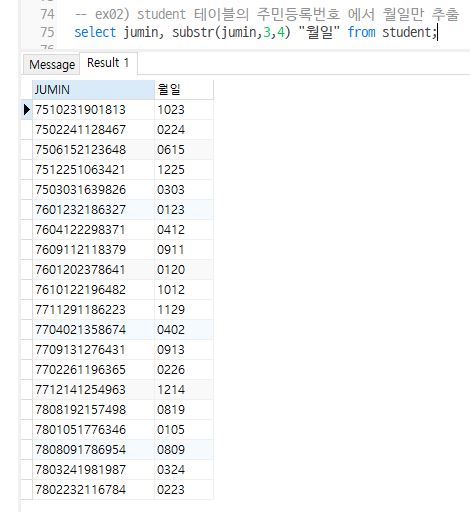
Q2. STUDENT 테이블의 주민등록번호(JUNIN)에서 월일만 추출{: .mt-2}
select jumin, substr(jumin,3,4) "월일" from student;
Q3. STUDENT 테이블의 주민등록번호(JUNIN)에서 1전공이 101번인 학생들의 이름과 태어난 월일, 생일 하루 전 날짜를 출력{: .mt-2}
select name
, substr(jumin,3,4)
, substr(jumin,1,2) || '.' || substr(jumin,3,2) || '.' || substr(jumin,5,2) birthday
, birthday - 15
from student
where deptno1 = 101;

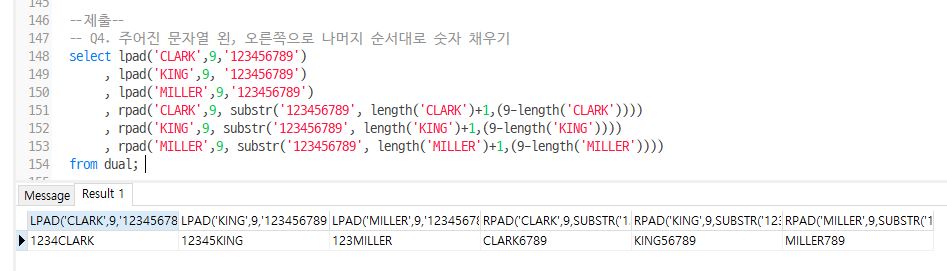
Q4. ‘CLARK’, ‘KING’, ‘MILLER’에 왼, 오른쪽으로 ‘123456789’를 채우는데 문자열의 나머지 순서대로 숫자 채우기
select lpad('CLARK',9,'123456789')
, lpad('KING',9, '123456789')
, lpad('MILLER',9,'123456789')
, rpad('CLARK',9, substr('123456789', length('CLARK')+1,(9-length('CLARK'))))
, rpad('KING',9, substr('123456789', length('KING')+1,(9-length('KING'))))
, rpad('MILLER',9, substr('123456789', length('MILLER')+1,(9-length('MILLER'))))
from dual;
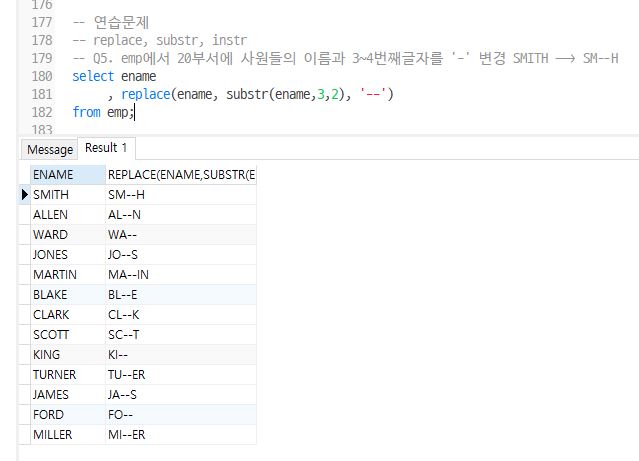
Q5. EMP 테이블에서 DEPTNO 20인 사원들의 이름과 3~4번째글자를 ‘-‘ 변경
ex) SMITH –> SM–H
select ename
, replace(ename, substr(ename,3,2), '--')
from emp;
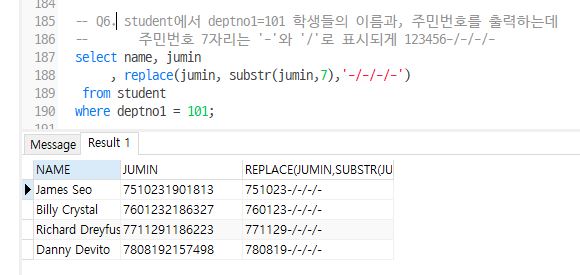
Q6. STUDENT 테이블에서 DEPTNO1 101 학생들의 이름과, 주민번호를 출력, 주민번호 7자리는 ‘-‘와 ‘/’로 표시
ex) 123456-/-/-/-
select name, jumin
, replace(jumin, substr(jumin,7),'-/-/-/-')
from student
where deptno1 = 101;
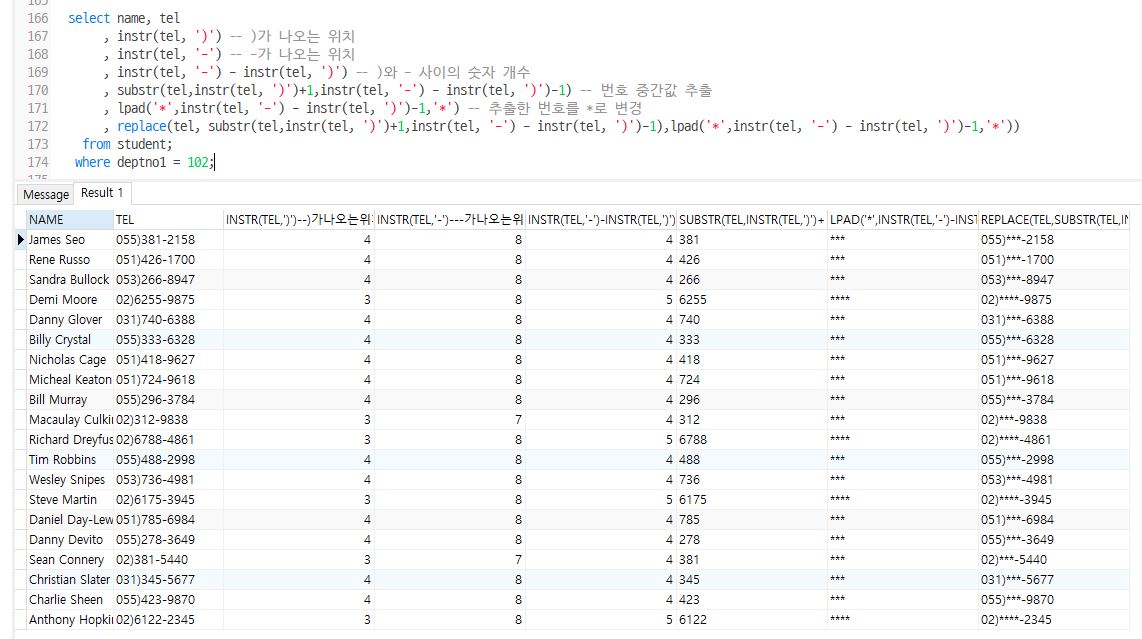
Q7. STUDENT 테이블에서 DEPTNO1 102 학생들의 이름과 전화번호를 출력, 전화번호는 국번만 ‘*‘처리
ex) 051)999-9999 –> 051)***-9999
select name, tel
, instr(tel, ')') -- )가 나오는 위치
, instr(tel, '-') -- -가 나오는 위치
, instr(tel, '-') - instr(tel, ')') -- )와 - 사이의 숫자 개수
, substr(tel,instr(tel, ')')+1,instr(tel, '-') - instr(tel, ')')-1) -- 번호 중간값 추출
, lpad('*',instr(tel, '-') - instr(tel, ')')-1,'*') -- 추출한 번호를 *로 변경
, replace(tel, substr(tel,instr(tel, ')')+1,instr(tel, '-') - instr(tel, ')')-1),lpad('*',instr(tel, '-') - instr(tel, ')')-1,'*'))
from student;
where deptno1 = 102;
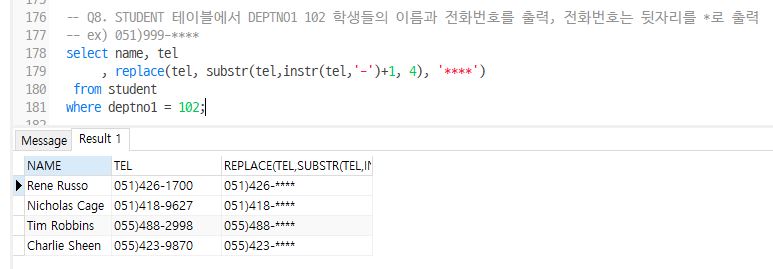
Q8. STUDENT 테이블에서 DEPTNO1 102 학생들의 이름과 전화번호를 출력, 전화번호는 뒷자리를 *로 출력
ex) 051)999-**
select name, tel
, replace(tel, substr(tel,instr(tel,'-')+1, 4), '****')
from student
where deptno1 = 102;