SQL Group Function
Table of contents
Group Functions
테이블의 전체 데이터에서 통계적인 결과를 구하기 위해 행 집합에 적용하여 하나의 결과를 생산하는 함수
▸ 두번 까지 중첩가능
count()
조회되는 데이터들의 총 건수
▸ 조건에 맞는 row의 갯수를 출력
▸ 중복되는 값 상관없이 데이터만 있다면 갯수를 셈(null값 제외)
syntax
count(칼럼명)
select count(*) from emp;
select count(sal) from emp;
select count(job) from emp; -- 중복되는 값이 있어도 갯수를 셈
select count(comm) from emp; -- null 값 포함하지 않음
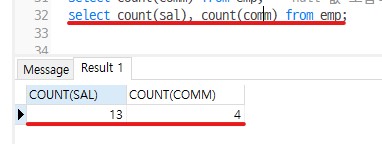
select count(sal), count(comm) from emp;
sum()
조회되는 데이터들을 총 합계
▸ 값이 숫자여야지 오류가 나지 않음
syntax
sum(칼럼명)
select sum(ename) from emp; -- 에러
select sum(sal) from emp;
select count(ename), sum(sal), round(sum(sal)/count(ename),0) from emp;

avg()
조회되는 데이터들을 평균
▸ avg는 null값을 빼고 평균을 구함
syntax
avg(칼럼명)
-- Q1) 평균급여 구하기
-- sum/count 사용한것과 동일하게 결과가 나옴
select round(avg(sal), 0) 평균급여
, round(sum(sal) / count(ename), 0) --위와 같은 결과
from emp;
-- Q2) Null값 포함/미포함 평균 구하기
-- avg는 null값을 빼고 평균을 구함
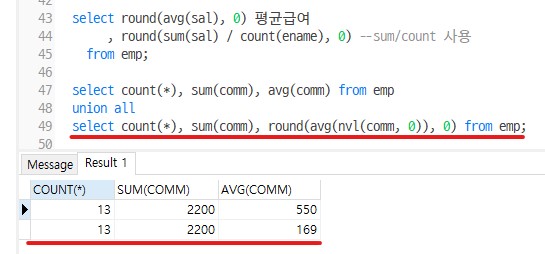
select count(*), sum(comm), avg(comm) from emp --미포함
union all
select count(*), sum(comm), round(avg(nvl(comm, 0)), 0) from emp; --포함
max() / min()
▸ 문자열은 a에 가까울수록 값이 낮다
syntax
max(칼럼명) : 조회되는 데이터들중 최대값
min(칼럼명) : 조회되는 데이터들중 최소값
-- Q1) 최소급여, 최대급여 구하기
select min(sal), max(sal) from emp;
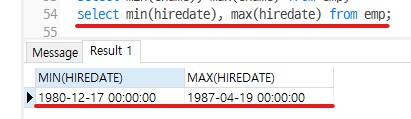
-- Q1) 가장 빠른 입사일, 가장 늦은 입사일 구하기
select min(hiredate), max(hiredate) from emp;
stddev()
조회되는 데이터들을 표준편차값
syntax
stddev(칼럼명)
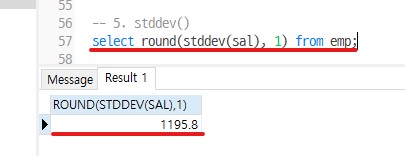
-- Q1) 급여의 표준편차 값 구하기
select round(stddev(sal), 1) from emp;
variance()
조회되는 데이터들의 분산값
syntax
stddev(칼럼명)
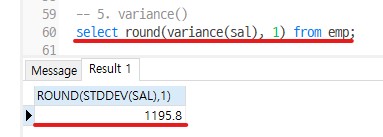
-- Q1) 급여의 표준편차 값 구하기
select round(variance(sal), 1) from emp;
Examples
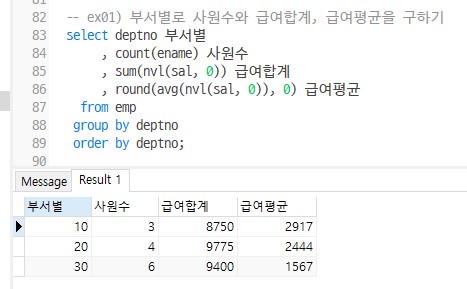
Q1. 부서별로 사원수와 급여합계, 급여평균을 구하기
select deptno
, count(ename)
, sum(nvl(sal, 0))
, round(avg(nvl(sal, 0)), 0)
from emp
group by deptno
order by deptno;
Q2. 업무별(JOB)로 인원수, 평균급여, 최고급여, 최소급여, 급여합계를 구하기
select job
, count(*)
, round(avg(nvl(sal, 0)), 2) 평균급여
, max(sal) 최고급여
, min(sal) 최소급여
, sum(sal) 급여합계
from emp
group by job;
Subtotal and Total Acquisition
rollup()
데이터의 소계, 총계를 그룹별로 구하기
★ 매개변수 안에 있는 열의 (그룹함수로 만들어진)행 값들을 다 더해
▸ rollup함수는 group by절과 같이 사용되면 group by절에 의해서 그룹 지어진 집합결과에 대해 좀더 상세한 결과를 반환
▸ group by rollup(deptno, job) → M+1개의 그룹이 생김
▸ rollup 매개변수 순서에 따라서 결과값이 달라짐
syntax
select [distinct] { * / column[alias]… }
from table
[where condition]
[group by rollup(컬럼명)]
[having group_condition]
[order by column];
-- ver1) union all을 사용해서 총계를 따로 더해주는 방법
select *
from (select job, sum(sal) from emp group by job
union all
select '총계', sum(sal) from emp) table1
order by job;
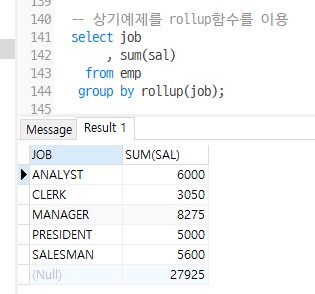
-- ver2) 상기예제를 rollup함수를 이용해서 총계를 구함
select job
, sum(sal)
from emp
group by rollup(job);
Example
Q1. EMP테이블에서 부서별, 직업별, 평균급여, 사원수를 부서별 합계와 전체 총계를 같이 출력하며, 부서번호와 직업을 순서로 작성
| 부서별 | 직업별 | 평균급여 | 사원수 |
|---|---|---|---|
| 부서 | 직업 | 평균급여 | 사원수 |
| 부서 | 부서별 합계 | 부서별 사원합계 | |
| 전체 합계 | 총사원수 |
union all
방법1
select * from( -- 부서, 직업, 평균급여, 사원수 출력 select deptno, job, round(avg(sal), 1) 평균급여, count(*) 사원수 from emp group by deptno, job union all -- 부서, 부서별 합계, 부서별 사원합계 출력 select deptno, null, round(avg(sal), 1) 평균급여, count(*) 사원수 from emp group by deptno union all -- 전체 합계, 총 사원수 출력 select null, null, round(avg(sal), 1) 평균급여, count(*) 사원수 from emp ) order by deptno, job; -- 부서번호와 직업 정렬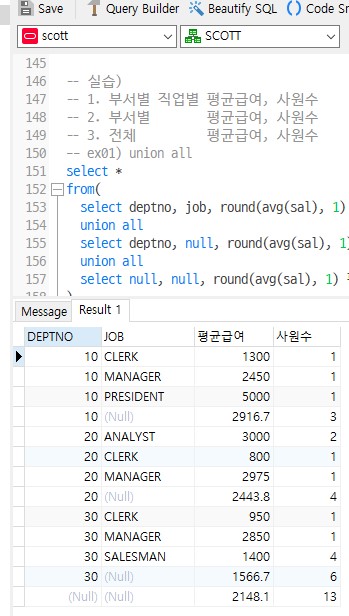
방법2 : null값에 이름 주기
select deptno --여기는 null 처리가 안됨 , nvl(job, '부서합계') JOB , 평균급여 , 사원수 from ( select deptno, job, round(avg(sal), 1) 평균급여, count(*) 사원수 from emp group by deptno, job union all select deptno, null, round(avg(sal), 1) 평균급여, count(*) 사원수 from emp group by deptno union all select null, null, round(avg(sal), 1) 평균급여, count(*) 사원수 from emp ) order by deptno, job;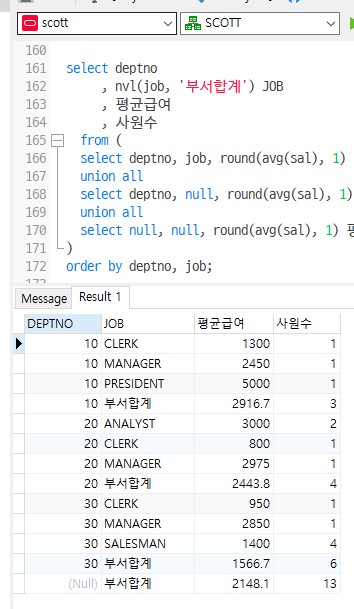
rollup()
방법1
select deptno , nvl(position, '-------------') position , 교수인원수 , 합계 from ( select deptno, position, count(*) 교수인원수, sum(pay) 합계 from professor group by deptno, position union all select deptno, null, count(*) 교수인원수, sum(pay) 합계 from professor group by deptno union all select null, null, count(*) 교수인원수, sum(pay) 합계 from professor ) order by deptno, position;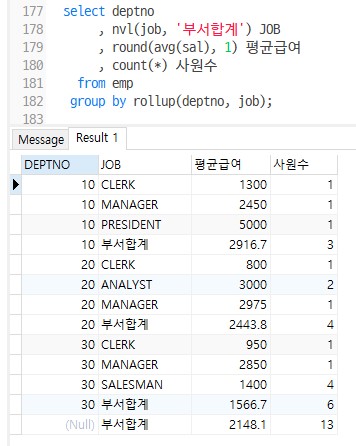
방법2
select deptno , nvl(job, '부서합계') , round(avg(sal), 1) 평균급여 , count(*) 사원수 from emp group by deptno, rollup(job);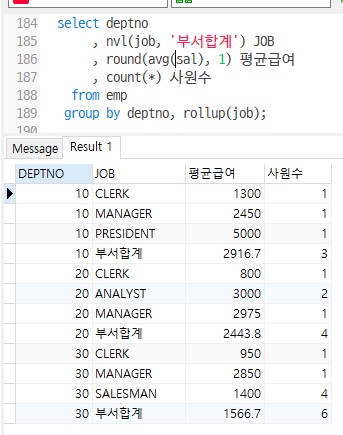
방법3
select deptno , nvl(job, '부서합계') , round(avg(sal), 1) 평균급여 , count(*) 사원수 from emp group by job, rollup(deptno);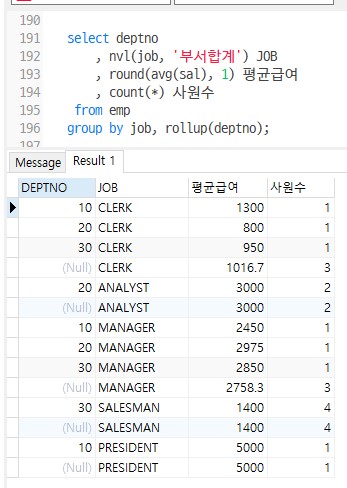
Q2. Professor 테이블에서 deptno, position별로 교수인원수, 급여합계 구하기
union all
select deptno , nvl(position, '-------------') position , 교수인원수 , 합계 from ( select deptno, position, count(*) 교수인원수, sum(pay) 합계 from professor group by deptno, position union all select deptno, null, count(*) 교수인원수, sum(pay) 합계 from professor group by deptno union all select null, null, count(*) 교수인원수, sum(pay) 합계 from professor ) order by deptno, position;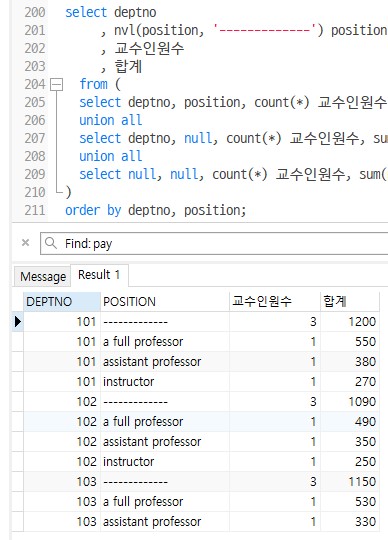
rollup()
select deptno , nvl(position, '--------------------') position , count(*) , sum(pay) from professor group by rollup(deptno, position);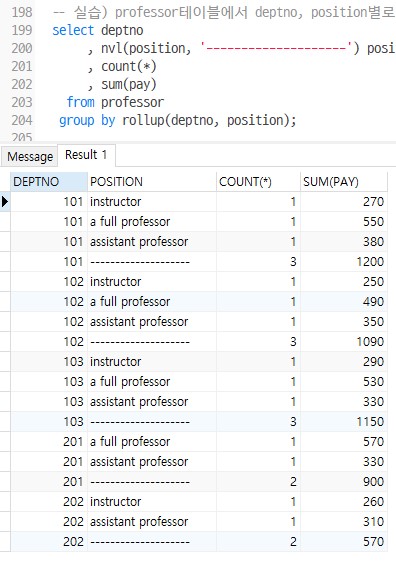
cube()
rollup 함수와 거의 비슷하지만, 출력방식이 다름
Example
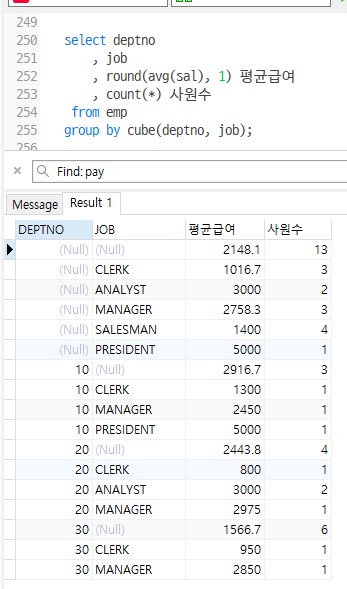
Q1. EMP테이블에서 부서별, 직업별, 평균급여, 사원수를 부서별 합계와 전체 총계를 같이 출력하며, 부서번호와 직업을 순서로 작성
| 부서별 | 직급별 | 평균급여 | 사원수 |
|---|---|---|---|
| 부서별 | 평균급여 | 사원수 | |
| 직급별 | 합계 | 사원수 | |
| 전체 합계 | 총사원수 |
select deptno
, job
, round(avg(sal), 1) 평균급여
, count(*) 사원수
from emp
group by cube(deptno, job);
Rank Function
순위함수 사용시에는 order by절은 필수로 정의
rank()
순위를 부여하는 함수로서 동일순위처리가 가능(중복순위 1,2,2,4)
컬럼명 안에 값이 없을 경우 에러가 나옴
syntax
특정자료의 순위 : rank(조건값) within group (order by 컬럼명[asc/desc])
전체자료의 순위 : rank() over(order by 컬럼명[asc/desc])
그룹별 순위 : rank() over(partition by 컬럼명 order by 컬럼명[asc/desc])
-- 1) 특정조건의 순위
-- SMITH가 알파벳순으로 몇번째인지?
select ename from emp order by ename;
select rank('SMITH') within group(order by ename) from emp;
select rank('SMITH') within group(order by hiredate) from emp; -- 에러
-- 2) 전체순위
-- emp에서 사원들의 급여순위?
select empno, ename, sal
, rank() over(order by sal) 급여오름차순
, rank() over(order by sal desc) 급여내림차순
from emp;
-- 3) 그룹별순위
-- 부서별 급여순위는?
select deptno, ename, sal
, rank() over(partition by deptno order by sal)
from emp;
![]()
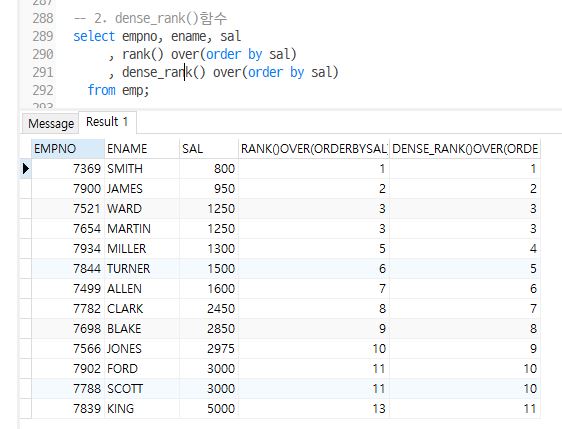
dense_rank()
동일순서의 처리에 영향이 없다 (중복순위, 1,2,2,3)
syntax
select dense_rank() over(order by 컬럼명) 별칭 from 테이블;
select empno, ename, sal
, dense_rank() over(order by sal)
from emp;
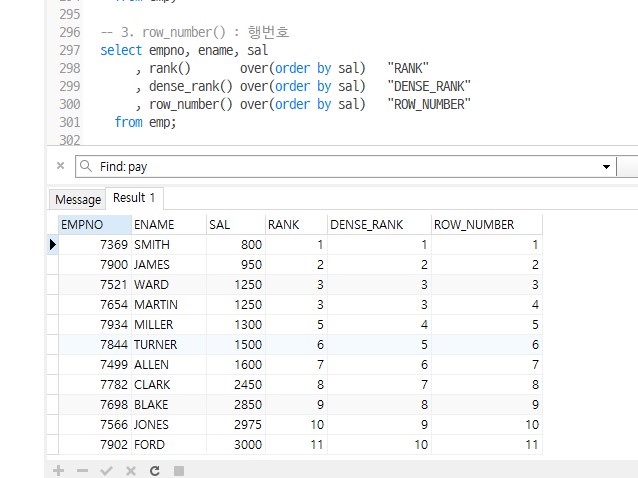
row_number()
특정순위의 일련번호를 제공하는 함수 동일순위처리 불가 (1,2,3,4,5)
syntax
select row_number() over(order by 컬럼명) 별칭 from 테이블;
select empno, ename, sal
, row_number() over(order by sal) "ROW_NUMBER"
from emp;
Other Functions
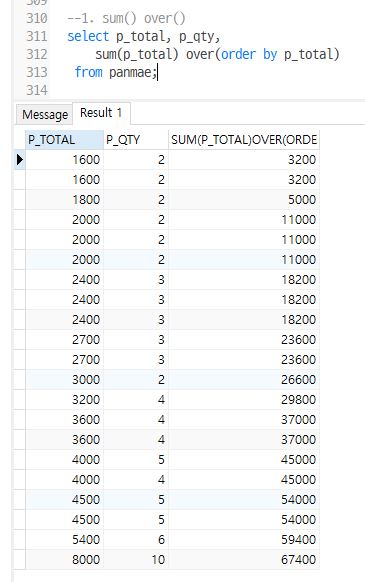
sum() over
누계를 구하는 함수
syntax
sum(컬럼) over (order by 컬럼(기준열))
select p_total, p_qty,
sum(p_total) over(order by p_total)
from panmae;
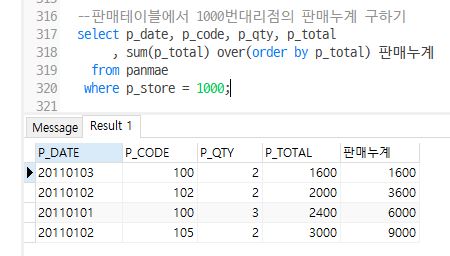
Example
Q1. 판매테이블에서 1000번대리점의 판매누계 구하기
select p_date, p_code, p_qty, p_total
, sum(p_total) over(order by p_total) 판매누계
from panmae
where p_store = 1000;
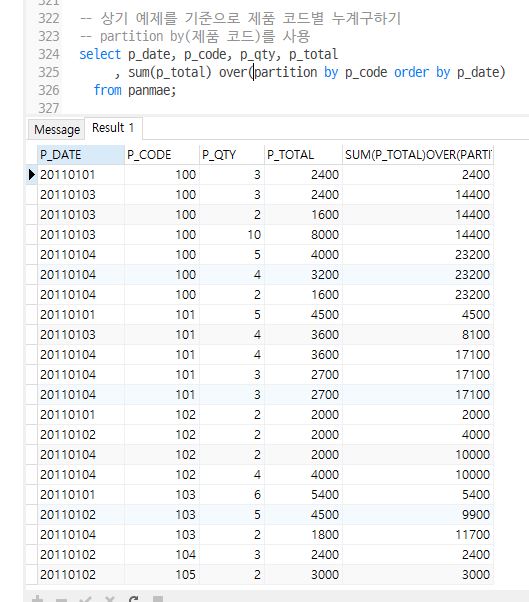
Q1-2. 상기 예제를 기준으로 제품 코드별 누계구하기, partition by(제품 코드)를 사용
select p_date, p_code, p_qty, p_total
, sum(p_total) over(partition by p_code order by p_date)
from panmae;
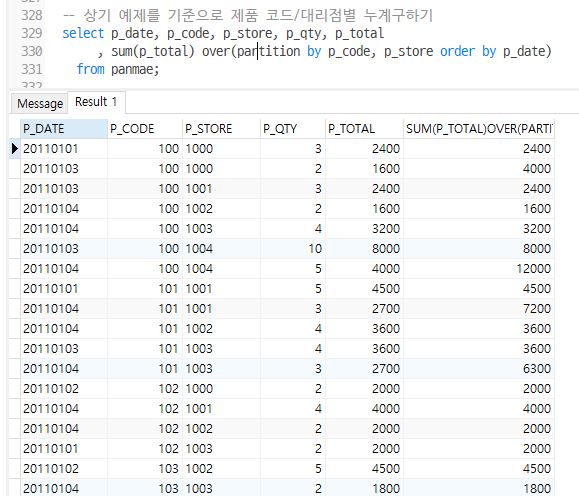
Q1-3. 상기 예제를 기준으로 제품 코드/대리점별 누계구하기
select p_date, p_code, p_store, p_qty, p_total
, sum(p_total) over(partition by p_code, p_store order by p_date)
from panmae;
ratio_to_report()
비율을 구하는 함수
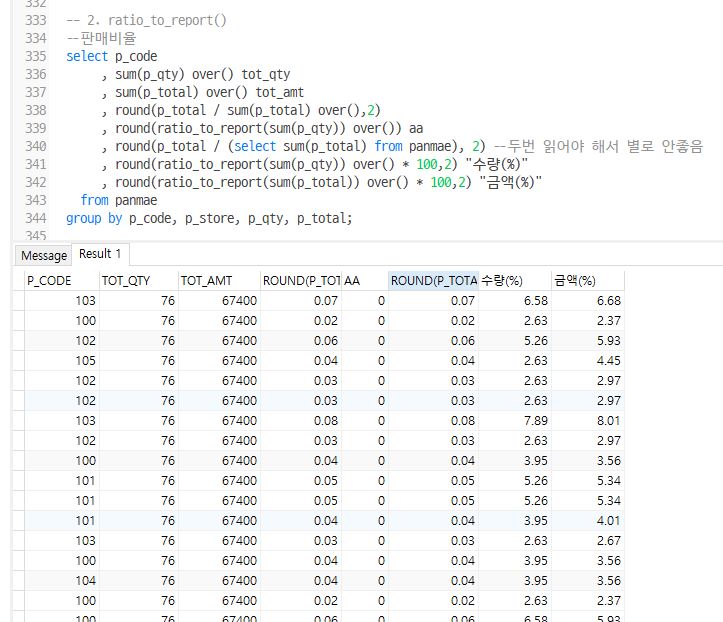
--판매비율
select p_code
, sum(p_qty) over() tot_qty
, sum(p_total) over() tot_amt
, p_store
, p_total
, round(p_total / sum(p_total) over(),2)
, round(p_total / (select sum(p_total) from panmae), 2) --두번 읽어야 해서 별로 안좋음
, round(ratio_to_report(sum(p_qty)) over() * 100,2) "수량(%)"
, round(ratio_to_report(sum(p_total)) over() * 100,2) "금액(%)"
from panmae
group by p_code, p_store, p_qty, p_total;
10. groupingset()
11. listagg()
12. pivot() / unpivot() - 행을 열로, 열을 행으로
13. lag()
14. lead()
Example
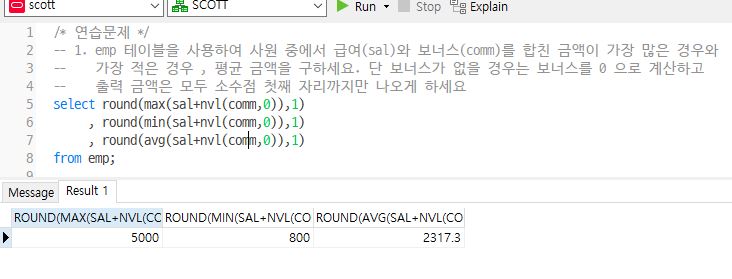
Q1. emp 테이블을 사용하여 사원 중에서 급여(sal)와 보너스(comm)를 합친 금액이 가장 많은 경우와 가장 적은 경우 , 평균 금액을 구하세요. 단 보너스가 없을 경우는 보너스를 0 으로 계산하고 출력 금액은 모두 소수점 첫째 자리까지만 나오게 하세요
select round(max(sal+nvl(comm,0)),1)
, round(min(sal+nvl(comm,0)),1)
, round(avg(sal+nvl(comm,0)),1)
from emp;
Q2. student 테이블의 birthday 컬럼을 참조해서 월별로 생일자수를 출력하세요
– TOTAL, JAN, …, 5 DEC
– 20EA 3EA ….
select count(*) TOTAL
, count(case when substr(birthday, 6, 2) ='01' then 1 END) JAN
, count(case when substr(birthday, 6, 2) ='02' then 1 END) FEB
, count(case when substr(birthday, 6, 2) ='03' then 1 END) MAR
, count(case when substr(birthday, 6, 2) ='04' then 1 END) APR
, count(case when substr(birthday, 6, 2) ='05' then 1 END) MAY
, count(case when substr(birthday, 6, 2) ='06' then 1 END) JUN
, count(case when substr(birthday, 6, 2) ='07' then 1 END) JUL
, count(case when substr(birthday, 6, 2) ='08' then 1 END) AUG
, count(case when substr(birthday, 6, 2) ='09' then 1 END) SEP
, count(case when substr(birthday, 6, 2) ='10' then 1 END) OCT
, count(case when substr(birthday, 6, 2) ='11' then 1 END) NOV
, count(case when substr(birthday, 6, 2) ='12' then 1 END) DEC
from student;

Q3. Student 테이블의 tel 컬럼을 참고하여 아래와 같이 지역별 인원수를 출력하세요.
단, 02-SEOUL, 031-GYEONGGI, 051-BUSAN, 052-ULSAN, 053-DAEGU, 055-GYEONGNAM 으로 출력하세요
select count(*) TOTAL
, count(case when substr(tel,1,instr(tel,')')-1) = '02' then 1 END) "02-SEOUL"
, count(case when substr(tel,1,instr(tel,')')-1) = '031' then 1 END) "31-GYEONGGI"
, count(case when substr(tel,1,instr(tel,')')-1) = '051' then 1 END) "051-BUSAN"
, count(case when substr(tel,1,instr(tel,')')-1) = '052' then 1 END) "052-ULSAN"
, count(case when substr(tel,1,instr(tel,')')-1) = '053' then 1 END) "053-DAEGU"
, count(case when substr(tel,1,instr(tel,')')-1) = '055' then 1 END) "055-YEONGNAM"
from student;

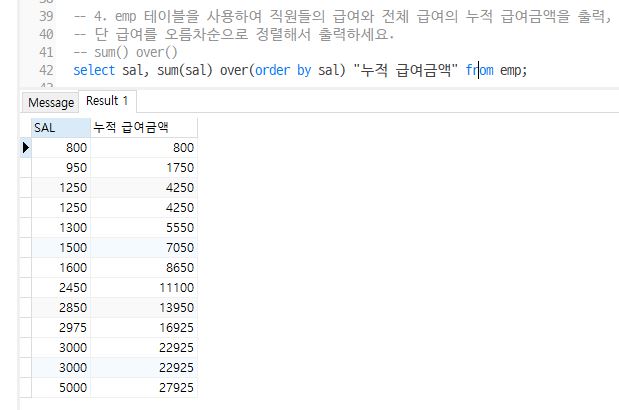
Q4. emp 테이블을 사용하여 직원들의 급여와 전체 급여의 누적 급여금액을 출력, 단 급여를 오름차순으로 정렬해서 출력하세요.
– sum() over()
select sal, sum(sal) over(order by sal) "누적 급여금액" from emp;
Q5. student 테이블의 Tel 컬럼을 사용하여 아래와 같이 지역별 인원수와 전체대비 차지하는 비율을 출력하세요.
(단, 02-SEOUL, 031-GYEONGGI, 051-BUSAN, 052-ULSAN, 053-DAEGU,055-GYEONGNAM)
select count(*) TOTAL
, count(case when substr(tel,1,instr(tel,')')-1) ='02' then 1 END) "02-SEOUL"
, count(case when substr(tel,1,instr(tel,')')-1) ='031' then 1 END) "031-GYEONGGI"
, count(case when substr(tel,1,instr(tel,')')-1) ='051' then 1 END) "051-BUSAN"
, count(case when substr(tel,1,instr(tel,')')-1) ='052' then 1 END) "052-ULSAN"
, count(case when substr(tel,1,instr(tel,')')-1) ='053' then 1 END) "053-DAEGU"
, count(case when substr(tel,1,instr(tel,')')-1) ='055' then 1 END) "055-GYEONGNAM"
, round(count(case when substr(tel,1,instr(tel,')')-1) ='02' then 1 END) / count(*) * 100, 2) "서울비율(%)"
, round(count(case when substr(tel,1,instr(tel,')')-1) ='031' then 1 END) / count(*) * 100, 2) "경기비율(%)"
, round(count(case when substr(tel,1,instr(tel,')')-1) ='051' then 1 END) / count(*) * 100, 2) "부산비율(%)"
, round(count(case when substr(tel,1,instr(tel,')')-1) ='052' then 1 END) / count(*) * 100, 2) "울산비율(%)"
, round(count(case when substr(tel,1,instr(tel,')')-1) ='053' then 1 END) / count(*) * 100, 2) "대구비율(%)"
, round(count(case when substr(tel,1,instr(tel,')')-1) ='055' then 1 END) / count(*) * 100, 2) "경남비율(%)"
from student;

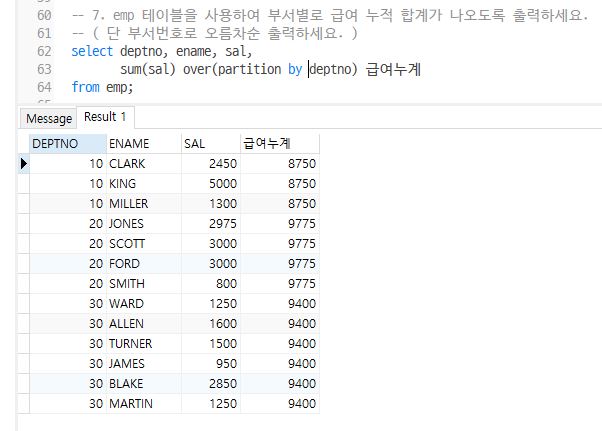
Q6. emp 테이블을 사용하여 부서별로 급여 누적 합계가 나오도록 출력하세요. ( 단 부서번호로 오름차순 출력하세요. )
select deptno, ename, sal,
sum(sal) over(partition by deptno) 급여누계
from emp;
Q8. emp 테이블을 사용하여 각 사원의 급여액이 전체 직원 급여총액에서 몇 %의 비율을 차지하는지 출력하세요. 단 급여 비중이 높은 사람이 먼저 출력되도록 하세요
select ename, sal
, round(ratio_to_report(sal) over() * 100,2) "%비중"
from emp;

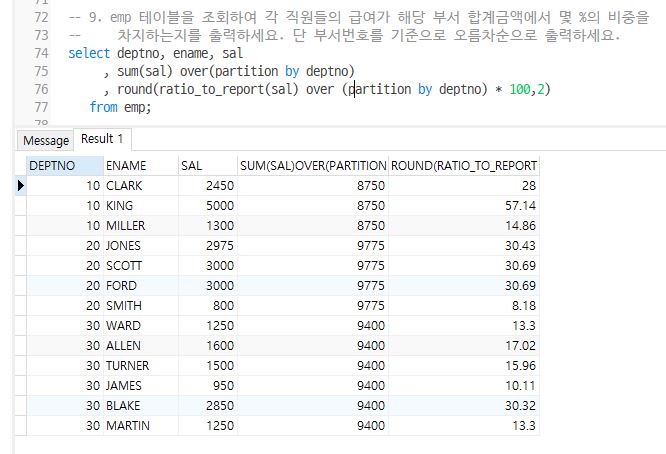
Q9. emp 테이블을 조회하여 각 직원들의 급여가 해당 부서 합계금액에서 몇 %의 비중을 차지하는지를 출력하세요. 단 부서번호를 기준으로 오름차순으로 출력하세요.
select deptno, ename, sal
, sum(sal) over(partition by deptno)
, round(ratio_to_report(sal) over (partition by deptno) * 100,2)
from emp;
Q10. emp 테이블을 조회하여 이름이 ‘ALLEN’ 인 사원의 사번과 이름과 연봉을 출력하세요. 단 연봉은 (sal * 12)+comm 로 계산하고 천 단위 구분기호로 표시하세요.
select * from emp;
select empno, ename, to_char((sal*12)+comm, '99,999') from emp where ename='ALLEN';
Q11. professor 테이블을 조회하여 201 번 학과에 근무하는 교수들의 이름과 급여, 보너스, 연봉을 아래와 같이 출력하세요. 단 연봉은 (pay*12)+bonus로 계산합니다.
select * from professor;
select name, pay , NVL(bonus,0), to_char((pay*12)+NVL(bonus,0), '$9,999') 연봉
from professor
where deptno = '201';
Q12. emp 테이블을 조회하여 comm 값을 가지고 있는 사람들의 empno , ename , hiredate, 총연봉,15% 인상 후 연봉을 아래 화면처럼 출력하세요. 단 총연봉은 (sal*12)+comm 으로 계산하고 15% 인상한 값은 총연봉의 15% 인상 값입니다.
(HIREDATE 컬럼의 날짜 형식과 SAL 컬럼 , 15% UP 컬럼의 $ 표시와 , 기호 나오게 하세요)
select * from emp;
select empno , ename , to_char(hiredate, 'YYYY-MM-DD') hiredate, to_char((sal*12)+NVL(comm,0), '$99,999,999') 총연봉, to_char((((sal*12)+NVL(comm,0))* 1.15), '$99,999,999') "15% 인상 후 연봉" from emp;