DQL Commands Select
Table of contents
- Select Statement Basic
- Columns with Expression
- distinct Clause
- Where Clause
- Group By Clause
- Having Clause
- Order By Clause
- DUAL table
Select Statement Basic
Select basic
테이블에 저장된 데이터를 검색하기 위한 명령문
▸ * = 에스테리스크
▸ 여러개의 절(clause)로 구성, 가독성을 위해 줄 구분과 들여쓰기를 함
▸ 명령어는 대소문자를 구분하지 않음
▸ []안에 있는 절은 생략 가능함
syntax
select [distinct] { * / column[alias]… }
from table
[where condition]
[group by groub_by_expression]
[having group_condition]
[order by column];
| 절 | 기능 |
|---|---|
| SELECT 절 | 조회하고자 하는 칼럼명의 리스트를 나열 |
| DISTINCT 절 | 동일한 내용(데이터)를 한번씩만 출력하여 중복을 제거 |
| FROM 절 | 조회하고자 하는 테이블명의 리스트를 나열 |
| WHERE 절 | 조회하고자 하는 로우의 조건을 나열 |
| GROUP BY 절 | 동일한 값을 갖는 롱들을 한 그룹으로 묶음 |
| HAVING 절 | 로우들의 그룹이 만족해야 하는 조건을 제시 |
| ORDER BY 절 | 로우들의 정렬 순서를 제시 |
Columns with Expression
테이블의 열(column)에 영향이 있음
syntax
select [distinct] { * / column[alias]… }
from table
[where condition]
[group by groub_by_expression]
[having group_condition]
[order by column];
Basic Column Expression
기본적인 행 나열 방법
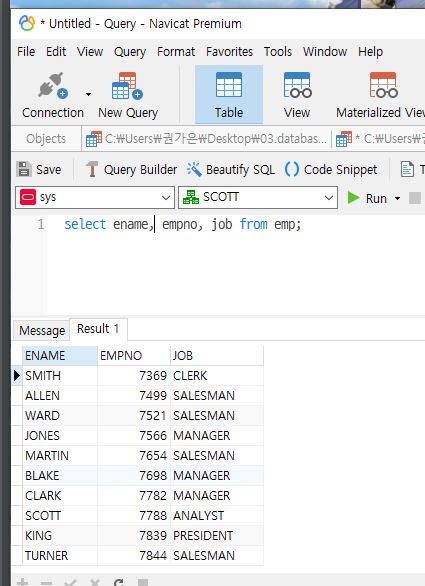
select * from emp;
-- emp 전체 테이블 조회
select ename, empno, job from emp;
-- ename, empno, job 컬럼 조회
Expression
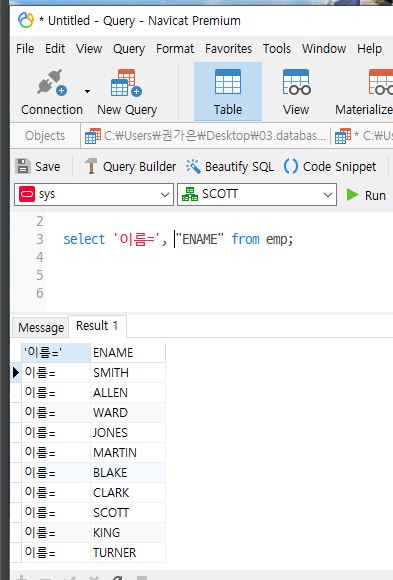
‘리터럴, 상수, 문자’의 표현식은 작은 따옴표로 정의해야 함
▸ 큰따옴표 에러, 큰따옴표는 별칭을 지정할때만 사용
▸ 컬럼명은 소문자, 대문자 상관하지 않음, 큰따옴표로 정의할 경우에는 대문자 사용
select '이름=', ename from emp;
-- 정상
select '이름=', ENAME from emp;
-- 정상
select "이름=", ename from emp;
-- 에러 : 큰따옴표
select '이름=', "ENAME" from emp;
-- 정상
select '이름=', "ename" from emp;
-- 에러 : 컬럼명을 소문자 큰따옴표
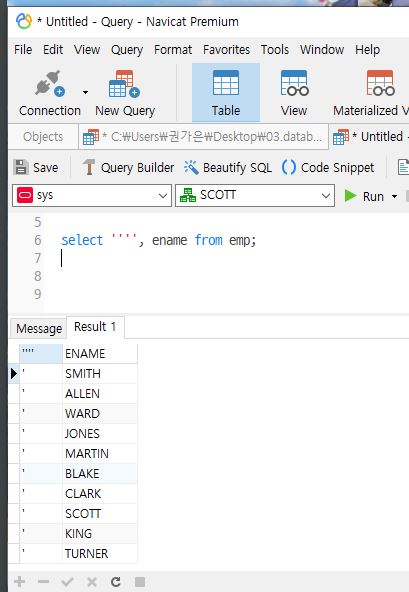
String
문자열 사용할때는 주의해야 함, 작은 따옴표 안에 작은 따옴표 nesting 불가 (에러)
select '한"글', ename from emp;
-- 쌍 따옴표는 가능
select '''', ename from emp;
-- 가능, 두번 동시에 사용해야 함
select '한'글', ename from emp;
-- 에러
Alias
별칭, 해당객체 또는 컬럼명을 다른 이름으로 정의
▸ as는 생략가능
▸ 별칭이 컬럼명이 되고 그냥 적거나 쌍따옴표로 적어야 함
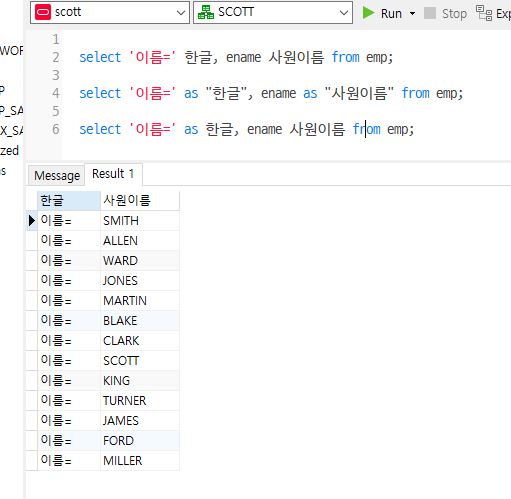
select '이름=' 한글, ename 사원이름 from emp;
select '이름=' as "한글", ename as "사원이름" from emp;
select '이름=' as 한글, ename 사원이름 from emp;
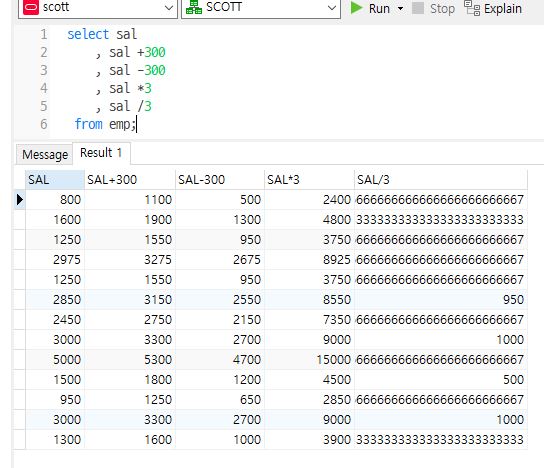
Arithmetic Operators
+ - * /
칼럼 값에 수학에서 사용하는 산술 연산자를 적용해 계산된 결과 값을 출력할 수 있음
▸ 숫자 또는 날짜 형태의 데이터 타입에만 사용이 가능
▸ 우선순위는 수학과 동일, 같은 우선순위일 경우 왼쪽에서 오른쪽, 우선순위 변경시 () 사용
select sal
, sal + 300
, sal - 300
, sal * 3
, sal / 3
from emp;
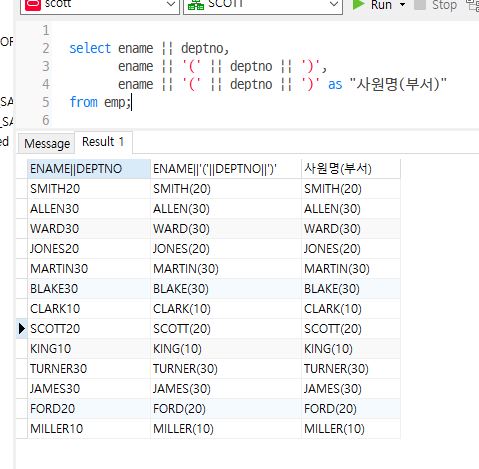
concat(),||
컬럼 및 문자열 연결
select ename || deptno from emp;
-- 연결 기본
select ename || '(' || deptno || ')' from emp;
-- 보기쉽게 연결됨
select ename || '(' || deptno || ')' as "사원명(부서)" from emp;
-- 보기좋게 연결됨 (컬럼명이 별칭으로 됨)
select ename || '(' || deptno || ')' as 사원명(부서) from emp;
-- ()는 표현식, 컬럼명으로 인식하기 때문에 문자로 사용하려면 큰따옴표로 감싸야 함
distinct Clause
동일한 내용을 한 번씩만 출력해 중복되는 데이터를 제거
▸ row에 영향이 있음
▸ 무조건 특정한 컬럼명보다 앞에 와야함
syntax
select [distinct] { * / column[alias]… }
from table
[where condition]
[group by groub_by_expression]
[having group_condition]
[order by column];
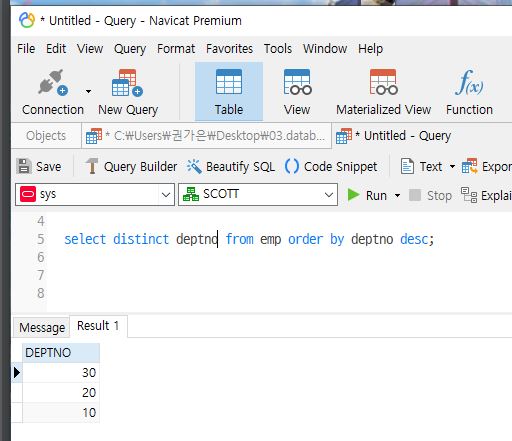
select distinct deptno from emp order by deptno;
--emp 테이블에서 deptno 중복을 제거한 값을 순서대로 나타냄
Where Clause
테이블에 저장된 데이터 중 원하는 데이터만 선택적으로 추출하기 위해 사용
▸ row에 영향이 있음
▸ 문자나 날짜 타입의 상수값은 반드시 작은 따옴표(‘‘)로 묶어 표현
▸ 영문자 상수값은 대소문자를 구분함
syntax
select [distinct] { * / column[alias]… }
from table
[where 조건문(condition)]
[group by groub_by_expression]
[having group_condition]
[order by column];
▸ condition에는 컬럼명, 연산자, 비교대상이 되는 상수값(숫자, 문자, 날짜)로 구성
Comparison Operator
숫자, 문자, 날짜의 크기나 순서를 비용하기 위해 사용
▸ 날짜 문자열을 비교하기 위해서는 문자상수와 마찬가지로 작은 따옴표로 묶어줘야 함
| 연산자 | 의미 |
|---|---|
| = | 비교대상과 같은 조건을 검색 |
| !=, <> | 같지 않다 |
| > | 크다 |
| >= | 크거나 같다 |
| < | 작다 |
| <= | 작거나 같다 |
syntax
where 컬럼명 Comparison Operator data
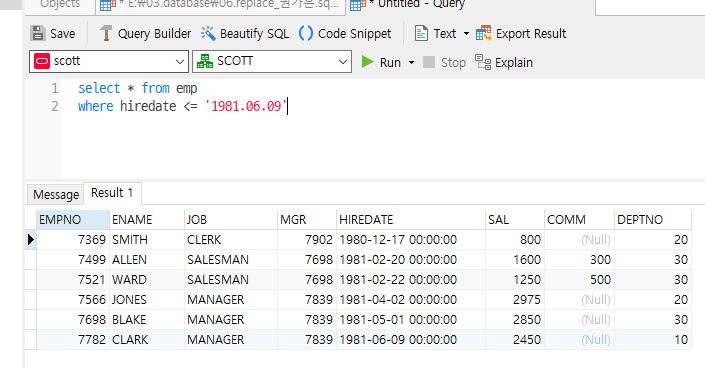
select * from emp
where hiredate <= '1981.06.09'
example
기본 연습
-- Q1. 사원번호가 7900인 자료만 조회하기
select * from emp where empno = 7900;
-- Q2. 급여(sal)가 900보다 작은 사원만 출력
select * from emp where sal < 900;
-- Q3. 이름이 smith인 사원만 출력
select * from emp where ename = 'SMITH';
--"와 공백은 같은것, '만 문자열로 나타남, 리터럴 값은 소문자 대문자 구별함
-- Q4. 입사일(hiredate) 1980-12-17인 사원만 출력
select * from emp where hiredate = '1980-12-17';
-- 형변환(암묵)되어서 date타입을 비교하게됨
select * from emp where hiredate = '19801217';
select * from emp where hiredate = '1980-dec-17';
select * from emp where hiredate = '1980-DEC-17';
select * from emp where hiredate = '1980.12.17';
select * from emp where hiredate = '80/12/17';
-- DB환경설정때문에 error
select * from emp where hiredate = '1980.80.17';
-- 80월이 시스템으로 없기때문에 error
select * from emp where hiredate = '1980.10.40';
-- 40일이 시스템으로 없기때문에 error
-- Q5. 기본 연산자를 이용해서 현재 급여를 인상
-- 인상전급여, 인상후급여 = 인상전급여의 10% 인상
select 인상전급여, 인상후 급여 from emp;
select sal 인상전급여 , sal*1.1 인상후급여 from emp;
select sal 인상전급여 , (sal*1.1 + 100)/2 인상후급여 from emp; --db에 전혀 영향이 안감, 조회만 하는것(select)
-- Q6. 급여가 4000보다 크거나 같은 사원만 출력
select * from emp where sal >= 4000;
select ename,sal from emp where 4000 <= sal;
-- Q7. 사원명이 'W'보다 크거나 같은 사원만 출력
select * from emp where ename >= 'W';
-- Q8. 급여가 2000보다 크면서 3000보다 작거나 같은 사원만 출력
select * from emp where sal between 2000 and 3000;
select * from emp where sal > 2000 and sal <= 3000;
연습 문제
-- ex01) 급여가 1000보다 작은 사원만 출력하기(ename/sal/hiredate 만 출력)
select ename, sal, hiredate from emp where 1000 > sal
-- ex02) 부서(dept)테이블에서 부서번호와, 부서명을 별칭으로 한 sql문을 작성
select * from dept
select deptno as 부서번호, dname as 부서명 from dept
-- ex03) 사원테이블에서 직급만 출력하는데 중복되지 않게 출력하는 sql문
select distinct job from emp
-- ex04) 급여가 800인 사원만 조회
select * from emp where 800 = sal
select * from emp where '800' = sal --내부적으로 변환됨, 위보다 실행속도가 느리다
-- ex05) 사원명이 BLAKE인 사원만 출력
select * from emp where 'BLAKE' = ename
-- ex06) 사원이름 JAMES-MATIN사이의 사원을 사원번호, 사원명, 급여를 출력
-- and betweem 두가지 형태로 작성
select * from emp;
select * from emp where ename >= 'JAMES' and ename <= 'MATIN'
select * from emp where ename between 'JAMES' and 'MATIN' --실행속도가 더 빠름
Logical Operator
조건을 여러 개 조합해서 결과를 얻어야 할 경우에 조건을 연결해 주는 역할
▸ 조건문에는 where의 다양한 연산자로 표현된 식들이 들어갈 수 있음
| 연산자 | 의미 |
|---|---|
| AND | 두가지 이상의 조건 모두 만족해야만 검색 |
| OR | 두가지 이상의 조건 중에서 한가지만 만족해도 검색 가능 |
| NOT | 조건에 만족하지 못하는 것만 검색 |
syntax
where not 조건문 and / or 조건문
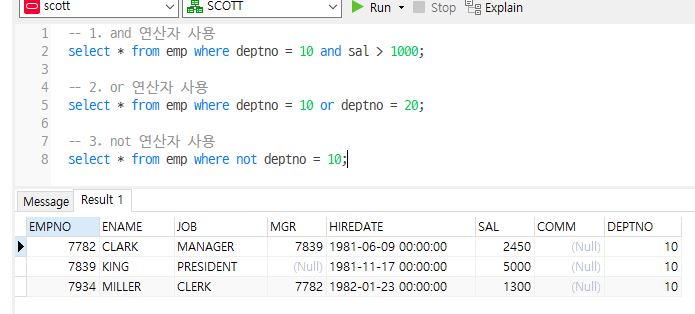
-- 1. and 연산자 사용
select * from emp where deptno = 10 and sal > 1000;
-- 2. or 연산자 사용
select * from emp where deptno = 10 or deptno = 20;
-- 3. not 연산자 사용
select * from emp where not deptno = 10;
example
연습문제
-- ex01) 입사일이 1982-01-01 이후이면서 급여가 3000보다 크거나 같은 사원목록
select * from emp where hiredate > '1982-01-01' and sal >=3000;
-- ex02) 입사일이 1982-01-01 이후이거나 급여가 3000보다 크거나 같은 사원목록
select * from emp where hiredate > '1982-01-01' or sal >=3000;
-- ex03) 사원이름은 S로 시작되면서 급여가 800인 사원
select * from emp where ename like 'S%' and sal = 800;
-- ex04) 급여가 1000보다 크면서 (comm이 1000보다 작거나 comm이 null) 인사원
select * from emp where (comm <1000 or comm is null) and sal > 1000;
between a and b
특정 칼럼의 데이터 값이 하한값과 상한값 사이에 포함되는 로우를 검색하기 위한 연산자
▸ 비교연산자와 논리연산자를 합친것과 같음
▸ 날짜나 문자 상수에 사용할 경우에는 작은 따옴표로 묶어줘야 함
SYNTAX
where 컬럼명 between A and B
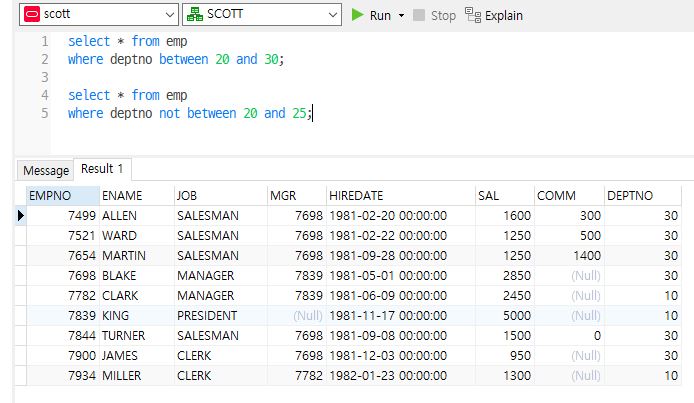
select * from emp
where deptno between 20 and 30;
-- and 연산자와 비교연산자를 사용한것과 같음
select * from emp
where deptno not between 20 and 25;
-- or 연산자와 비교연산자 사용한것과 같음
in(a,b,c)
특정 칼럼의 값이 A,B,C중에 하나라도 일치하면 참이 되는 연산자
▸ or 연산자를 사용한것과 동일함
▸ 앞에 not을 붙이면 <>, != 연산자를 사용한것과 동일함
SYNTAX
where 컬럼명 in(A,B,C)
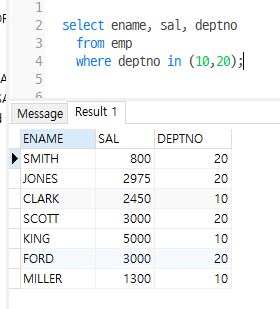
--1. emp에서 부서번호가 10, 20인 사원만 조회
select ename, sal, deptno
from emp where deptno in(10,20)
-- 위와 같은 방법이지만 코드가 길어지기 때문에 안좋음
select ename, sal, deptno
from emp where deptno = 10 or deptno = 20;
like Operator
칼럼에 저장된 문자 상수 중 like연산자에서 지정한 문자 패턴과 부분적으로 일치하면 참이 되는 연산자
▸ 데이터의 일부만 일치하더라도 조회가 가능하도록 하기 위해서 사용
▸ pattern에는 두가지가 있음
| 연산자 | 의미 |
|---|---|
| % | 문자가 없거나 하나 이상의 문자가 어떤 값이 와도 상관없음 |
| _ | 하나의 문자가 어떤 값이 와도 상관없음(_의 갯수만큼 따짐) |
SYNTAX
where 컬럼명 like pattern
select * from emp where ename like 'A%';
select * from emp where ename between 'A' and 'AZ';
--이름이 N으로 끝나는 사원
select * from emp where ename like '%N';
--이름에 A를 포함하는 사원
select * from emp where ename like '%A%';
--sal이 50으로 끝나는 사원만 출력
select * from emp where SAL like '%50';
--입사일이 1980년대 입사한 사람
select * from emp where HIREDATE like '198%';
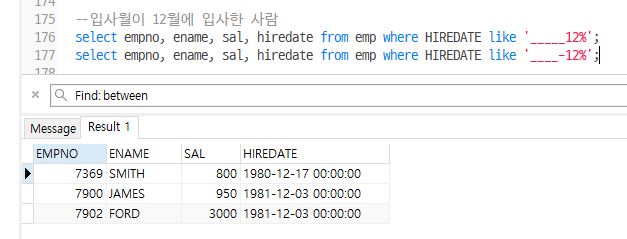
--입사월이 12월에 입사한 사람
select empno, ename, sal, hiredate from emp where HIREDATE like '_____12%';
select empno, ename, sal, hiredate from emp where HIREDATE like '____-12%';
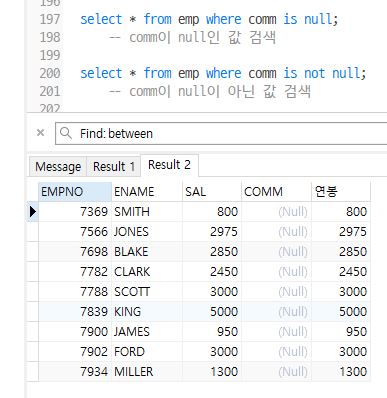
is null / is not null
is null 연산자는 칼럼 값 중에서 null을 포함하는 로우를 검색하기 위해 사용하는 연산자
▸ null이 저장되어 있는 경우에는 = 연산자로 판단할 수 없음
▸ is not null은 정의가 반대
SYNTAX
where 컬럼명 is null / is not null
select * from emp where comm is null;
-- comm이 null인 값 검색
select * from emp where comm is not null;
-- comm이 null이 아닌 값 검색
Group By Clause
그룹 함수의 결과를 조건에 따라 그룹화하기
▸ select절에 사용된 그룹함수 이외의 컬럼이나 표현식은 반드시 group by 절에 정의 되어야 함
▸ group by 절에 사용된 컬럼이라도 select절에 사용되지 않아도 됨
▸ group by 절에는 반드시 컬럼명이 사용되어야 함 (alias는 사용 불가)
▸ group by절을 사용한 select문에 order by절로 정렬을 하기 위해서는 order by절은 group by절 뒤에 정의해야 한다
→ (order by 절에서는 별칭도 정의가 가능)
syntax
select [distinct] { * / column[alias]… }
from table
[where 조건문(condition)]
[group by groub_by_expression]
[having group_condition]
[order by column_name(1,2,3…) sorting];
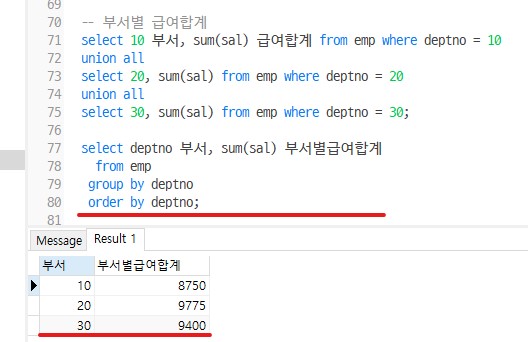
-- Q1) 부서별 급여합계
-- ver1) where 절
-- 데이터에 맞는 조건 하나씩(부서 하나의 급여합계)만 검색 가능하고,
-- 부서별로 급여 합계를 보려면 union all로 합쳐야지 한꺼번에 출력되기 때문에 불편함
select 10 부서, sum(sal) 급여합계 from emp where deptno = 10
union all
select 20, sum(sal) from emp where deptno = 20
union all
select 30, sum(sal) from emp where deptno = 30;
-- ver2) sum() 그룹함수
-- group by를 사용하면서 부서별로 급여 합계를 쉽게 볼 수 있음
select deptno 부서, sum(sal) 부서별급여합계
from emp
group by deptno
order by 부서;
Having Clause
having
집계함수를 가지고 그룹결과를 조건별로 결과 구하기
▸ 단일행 함수에서 사용했던 where조건과 동일
▸ 즉, 그룹화에서 조건을 주기위해서는 having절을 사용, where절에는 그룹화 되지 않은 행에서 단일 조건을 검색할 때 사용
▸ having절에는 집계함수를 가지고 조건을 비교할 때 사용되며 having절과 group by절과 함께 사용
▸ having절은 group by절없이 사용할 수 없고, order by 절보다 일찍 나옴
syntax
select [distinct] { * / column[alias]… }
from table
[where 조건문(condition)]
[group by groub_by_expression]
[having group_condition]
[order by column_name(1,2,3…) sorting];
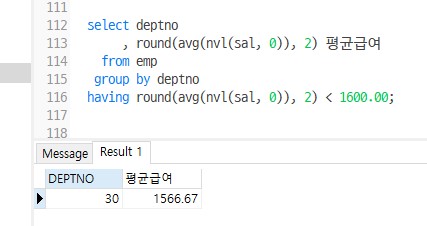
-- Q1) EMP테이블에서 평균 급여가 1600보다 낮은 부서번호와 평균급여를 출력
select deptno, round(avg(nvl(sal, 0)), 2) 평균급여
from emp
group by deptno
having round(avg(nvl(sal, 0)), 2) < 1600.00;
Order By Clause
특정 칼럼을 기준으로 순서대로 나열할 때 사용
▸ 등수정하기와 같음, ~부터, 기준으로, ~순으로
▸ 여러개의 칼럼값을 지정할 수 있음, 컴마로 구분하고 먼저 지정한 순서대로 나열됨
▸ asc 오름차순(문자 데이터로 지정하면 알파벳 순서대로 나옴), desc 내림차순
▸ 날짜 데이터로 지정하면 과거가 가장 먼저 나옴
syntax
select [distinct] { * / column[alias]… }
from table
[where 조건문(condition)]
[group by groub_by_expression]
[having group_condition]
[order by column_name(1,2,3…) sorting];
▸ column_name 여러개 설정 가능, 숫자로 설정하면 표현되는 컬럼을 기준으로 순서를 셈
select ename, sal, deptno
from emp
where deptno in (10,20)
order by deptno;
select ename, deptno, sal
from emp
where deptno in (10,20)
order by 1; -- 숫자는 열 번호 순서를 고름
select ename, deptno, sal
from emp
where deptno in (10,20)
order by 2, 3 asc; --먼저 정렬해야 하는걸 먼저 정렬함
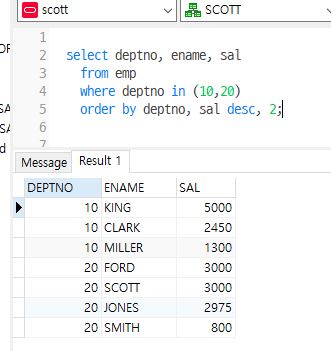
select deptno, ename, sal
from emp
where deptno in (10,20)
order by deptno, sal desc, 2;
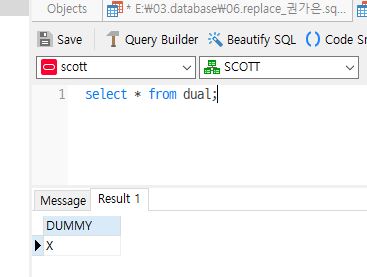
DUAL table
결과를 출력하기 위해 제공되는 테이블로 오라클에서 자동생성
▸ varchar2(1)으로 정의된 하나의 DUMMY 칼럼으로 구성되어 있고 데이터는 X
▸ 계산이나 함수를 실행하고 나서 결과값을 한번 표시하고 싶을 때 사용
select * from dual;